机器学习(Machine Learning)&深度学习(Deep Learning)资料(Chapter 2)
by ty4z2008 (廖君)
Source: https://github.com/ty4z2008/Qix/blob/master/dl2.md
介绍:使用卷积神经网络的图像缩放.
介绍:ICML2015 论文集,优化4个+稀疏优化1个;强化学习4个,深度学习3个+深度学习计算1个;贝叶斯非参、高斯过程和学习理论3个;还有计算广告和社会选择.ICML2015 Sessions.
介绍:使用卷积神经网络的图像缩放.
介绍:,第28届IEEE计算机视觉与模式识别(CVPR)大会在美国波士顿举行。微软研究员们在大会上展示了比以往更快更准的计算机视觉图像分类新模型,并介绍了如何使用Kinect等传感器实现在动态或低光环境的快速大规模3D扫描技术.
介绍:(文本)机器学习可视化分析工具.
介绍:机器学习工具包/库的综述/比较.
介绍:数据可视化最佳实践指南.
介绍:Day 1、Day 2、Day 3、Day 4、Day 5.
介绍:深度学习之“深”——DNN的隐喻分析.
介绍:混合密度网络.
介绍:数据科学家职位面试题.
介绍:准确评估模型预测误差.
介绍:Continually updated Data Science Python Notebooks.
介绍:How to share data with a statistician.
介绍:来自Facebook的图像自动生成.
介绍:How to share data with a statistician.
介绍:(Google)神经(感知)会话模型.
介绍:The 50 Best Masters in Data Science.
介绍:NLP常用信息资源.
介绍:语义图像分割的实况演示,通过深度学习技术和概率图模型的语义图像分割.
介绍:Caffe模型/代码:面向图像语义分割的全卷积网络,模型代码.
介绍:深度学习——成长的烦恼.
介绍:基于三元树方法的文本流聚类.
介绍:Free Ebook:数据挖掘基础及最新进展.
介绍:深度学习革命.
介绍:数据科学(实践)权威指南.
介绍:37G的微软学术图谱数据集.
介绍:生产环境(产品级)机器学习的机遇与挑战.
介绍:神经网络入门.
介绍:来自麻省理工的结构化稀疏论文.
介绍:来自雅虎的机器学习小组关于在线Boosting的论文 .
介绍:20个最热门的开源(Python)机器学习项目.
介绍:C++并行贝叶斯推理统计库QUESO,github code.
介绍:Nature:LeCun/Bengio/Hinton的最新文章《深度学习》,Jürgen Schmidhuber的最新评论文章《Critique of Paper by “Deep Learning Conspiracy” (Nature 521 p 436)》.
介绍:基于Scikit-Learn的预测分析服务框架Palladium.
介绍:John Langford和Hal Daume III在ICML2015上关于Learning to Search的教学讲座幻灯片.
介绍:读完这100篇论文 就能成大数据高手,国内翻译.
介绍:NLP课程《社交媒体与文本分析》精选阅读列表.
介绍:写给开发者的机器学习指南.
介绍:基于维基百科的热点新闻发现.
介绍:(Harvard)HIPS将发布可扩展/自动调参贝叶斯推理神经网络.
介绍:面向上下文感知查询建议的层次递归编解码器.
介绍:GPU上基于Mean-for-Mode估计的高效LDA训练.
介绍:从实验室到工厂——构建机器学习生产架构.
介绍:适合做数据挖掘的6个经典数据集(及另外100个列表).
介绍:Google面向机器视觉的深度学习.
介绍:构建预测类应用时如何选择机器学习API.
介绍:Python+情感分析API实现故事情节(曲线)分析.
介绍:(R)基于Twitter/情感分析的口碑电影推荐,此外推荐分类算法的实证比较分析.
介绍:CMU(ACL 2012)(500+页)面向NLP基于图的半监督学习算法.
介绍:从贝叶斯分析NIPS,看同行评审的意义.
介绍:(RLDM 2015)计算强化学习入门.
介绍:David Silver的深度强化学习教程.
介绍:深度神经网络的可解释性.
介绍:Spark快速入门.
介绍:TalkingMachines:面向体育/政治和实时预测的机器学习.
介绍:Stanford社交网络与信息网络分析课程资料+课设+数据.
介绍:David Silver(DeeMind)的强化学习课程,slide.
介绍:基于Theano/GPU的高效深度学习.
介绍:来自微软的.
介绍:(Go)情感分析API服务Sentiment Server.
介绍:受限波尔兹曼机初学者指南.
介绍:Mining and Summarizing Customer Reviews ,Mining High-Speed Data Streams,Optimizing Search Engines using Clickthrough Data.
介绍:Nvidia深度学习课程.
介绍:2015年深度学习暑期课程,推荐讲师主页.
介绍:这是一篇关于百度文章《基于深度学习的图像识别进展:百度的若干实践》的摘要,建议两篇文章结合起来阅读.
介绍:视频标注中的机器学习技术.
介绍:博士论文:(Ilya Sutskever)RNN训练.
介绍:深度神经网络的灰色区域:可解释性问题,中文版.
介绍:Golang 实现的机器学习库资源汇总.
介绍:深度学习的统计分析.
介绍:面向NLP的深度学习技术与技巧.
介绍:Kaggle’s CrowdFlower竞赛NLP代码集锦.
介绍:斯坦福的自然语言理解课程.
介绍:Deep Learning与Shallow Learning 介绍
介绍:这是一本机器学习的电子书,作者Max Welling先生在机器学习教学上面有着丰富的经验,这本书小但精致.
介绍:由荷兰阿姆斯特丹大学 & 谷歌瑞士著.
介绍:介绍个乐于总结和翻译机器学习和计算机视觉类资料的博客,包含的内容:Hinton的CSC321课程的总结;Deep Learning综述;Notes on CNN的总结;python的原理总结;Theano基础知识和练习总结;CUDA原理和编程;OpenCV一些总结.
介绍:针对具体问题(应用场景)如何选择机器学习算法(系列).
介绍:数据科学免费书分类集合
介绍:深度学习在语音合成最新进展有哪些?推荐MSRA的Frank Soong老师关于语音合成的深度学习方法的录像和幻灯片与以及谷歌的LSTM-RNN合成介绍,论文
介绍:新书(可免费下载):数据科学的艺术
介绍:模式识别与机器学习书籍推荐,本书是微软剑桥研究院大神Bishop所写,算是最为广为认知的机器学习教材之一,内容覆盖全面,难度中上,适合研究生中文版 or 备份
介绍:数据可视化介绍(23页袖珍小册子)
介绍:这篇论文荣获EMNLP2015的最佳数据/资源奖优秀奖,标注的推特数据集
介绍:作者在深度学习的思考.
介绍:数据可视化常用工具软件资源汇总
介绍:Buffalo大学教授Sargur Srihari的“机器学习和概率图模型”的视频课程
介绍:耶路撒冷希伯来大学教授Shai Shalev-Shwartz和滑铁卢大学教授Shai Ben-David的新书Understanding Machine Learning: From Theory to Algorithms,此书写的比较偏理论,适合对机器学习理论有兴趣的同学选读
介绍:机器学习学习清单
介绍:知乎上面的一篇关于NLP界有哪些神级人物?提问。首推Michael Collins
介绍:机器学习与NLP专家、MonkeyLearn联合创始人&CEO Raúl Garreta面向初学者大体概括使用机器学习过程中的重要概念,应用程序和挑战,旨在让读者能够继续探寻机器学习知识。
介绍:(IPN)基于Scikit-Learn的GBRT(Gradient Boost Regression Tree)教程,slide
介绍: 无需做深度学习就能用的分布式深度学习软件.
介绍: 在亚马逊数据和众包Mechanical Turk上,实现了来自彩票和拍卖的机制,以收集用户对产品的乐意购买价格(WTP,willingness-to-pay)训练集。 E-commerce Recommendation with Personalized Promotion [Zhao,RecSys15] 回归模型预测未知WTP,提升卖家利润和消费者满意度
介绍:来自伯克利分校的大规模机器学习.
介绍:来自52ml的机器学习资料大汇总.
介绍:这本书的作者McKeown是2013年世界首个数据科学院(位于哥伦比亚大学)主任,她亦是ACL、AAAI和ACM Fellow .
介绍:EMNLP-15文本摘要若干.
介绍:来自Netflix的Xavier Amatriain在Summer School 2014 @ CMU上长达4小时的报告,共248页,是对推荐系统发展的一次全面综述,其中还包括Netflix在个性化推荐方面的一些经验介绍.
介绍:(ECML PKDD 2015)大数据流挖掘教程,此外推荐ECML PKDD 2015 Tutorial列表.
介绍:Spark上的Keras深度学习框架Elephas.
介绍:Surya Ganguli深度学习统计物理学.
介绍:(系统/算法/机器学习/深度学习/图模型/优化/…)在线视频课程列表.
介绍:(PyTexas 2015)Python主题建模.
介绍:Hadoop集群上的大规模分布式机器学习.
介绍:基于LinkedIn数据得出的深度学习热门”东家”排行.
介绍:(c++)神经网络手把手实现教程.
介绍:香港中文大学汤晓鸥教授实验室公布的大型人脸识别数据集: Large-scale CelebFaces Attributes (CelebA) Dataset 10K 名人,202K 脸部图像,每个图像40余标注属性.
介绍:面向机器视觉的无监督特征学习,Ross Goroshin’s webpage.
介绍:谷歌研究院Samy Bengio等人最近写的RNN的Scheduled Sampling训练方法论文.
介绍:机器学习基本算法简要入门.
介绍:Github机器学习/数学/统计/可视化/深度学习相关项目大列表.
介绍:CMU的信息论课程.
介绍:谷歌研究院Samy Bengio等人最近写的RNN的Scheduled Sampling训练方法论文.
介绍:基于Hadoop集群的大规模分布式深度学习.
介绍:来自斯坦福大学及NVIDIA的工作,很实在很实用。采用裁剪网络连接及重训练方法,可大幅度减少CNN模型参数。针对AlexNet、VGG等模型及ImageNet数据,不损失识别精度情况下,模型参数可大幅度减少9-13倍.
介绍:无需做深度学习就能用的分布式深度学习软件,github.
介绍:当今世界最NB的25位大数据科学家,通过他们的名字然后放在google中搜索肯定能找到很多很棒的资源译文.
介绍:Nils Reimers面向NLP的深度学习(Theano/Lasagne)系列教程.
介绍:主讲人是陶哲轩,资料Probability: Theory and Examples,笔记.
介绍:数据科学(学习)资源列表.
介绍:应对非均衡数据集分类问题的八大策略.
介绍:重点推荐的20个数据科学相关课程.
介绍:递归神经网络.
介绍:(HOG)学习笔记.
介绍:计算建模/计算神经学课程汇总.
介绍:(Yelp)基于深度学习的商业图片分类.
介绍:免费在线书《Neural Networks and Deep Learning》神经网络与深度学习。目前提供了前四章的草稿,第一章通过手写数字识别的例子介绍NN,第二章讲反向传播算法,第三章讲反向传播算法的优化,第四章讲NN为什么能拟合任意函数。大量python代码例子和交互动画,生动有趣.中文版
介绍:数据科学大咖荐书(入门).
介绍:NLP 深度学习资源列表.
介绍:很多arXiv上面知名论文可以在这个网站找到github的项目链接.
介绍:深度学习在视觉跟踪的探索.
介绍:Spark机器学习入门实例——大数据集(30+g)二分类.
介绍:保罗艾伦人工智能实验室表示,Google Scholar是十年前的产物,他们现在想要做进一步的提高。于是推出了全新的,专门针对科学家设计的学术搜索引擎Semantic Scholar.
介绍:半监督学习,Chapelle.篇篇都是经典,作者包括Vapnik,Bengio,Lafferty,Jordan.此外推荐Xiaojin (Jerry) Zhu编写的Introduction to Semi-Supervised Learning.
介绍:Spark机器学习入门实例——大数据集(30+g)二分类.
介绍:为入门者准备的深度学习与神经网络免费资源.
介绍:Google 开源最新机器学习系统 TensorFlow,此外提供TensorFlow白皮书white paper of tensorflow 2015.hacker news,Google大牛解读TensorFlow
介绍:三星开源的快速深度学习应用程序开发分布式平台.
介绍:分布式机器学习工具包.
介绍:语义大数据——大数据/事件处理的语义方法.
介绍:LSTM(Long Short Term Memory)和RNN(Recurrent)学习教程.
介绍:Princeton Vision Group的深度学习库开源.
介绍:基于AWS的自动分布式科学计算库Ufora,Why I Open Sourced Five Years of Work.
介绍:(PyCon SE 2015)深度学习与深度数据科学.
介绍:推荐南京大学机器学习与数据挖掘研究所所长——周志华教授的Google学术主页.
介绍:免费书:面向数据科学的高级线性模型.
介绍:基于知识迁移的神经网络高效训练Net2Net.
介绍:徐亦达机器学习课程 Variational Inference.
介绍:深度神经网络结构学习.
介绍:来自斯坦福大学的Multimodal Deep Learning papers.
介绍:深度学习简析,TensorFlow,Torch,Theano,Mxnet.
介绍:这个专栏是一个stanford学生做的CS183c课程的一个note,该课程是由Reid Hoffman等互联网boss级人物开设的,每节课请一位巨头公司的相关负责人来做访谈,讲述该公司是怎么scale的。最新两期分别请到了雅虎的梅姐 和airbnb创始人Brian Chesky。.
介绍:基于分布式表示的自然语言理解(100+页),论文.
介绍:推荐系统手册.
介绍:理解LSTM网络翻译.
介绍:机器学习在quora中的应用.
介绍:思维学习——RL+RNN算法信息论.
介绍:数据科学家毕业后继续学习的5种方式.
介绍:深度学习在神经网络的应用.
介绍:上下文学习,代码.
介绍:机器学习零基础入门,代码.
介绍:2015年度CCF优秀博士学位论文奖论文列表.
介绍:Learning to Hash Paper, Code and Dataset.
介绍:(PyData2015)基于Theano/Lasagne的CNN/RNN教程,github.
介绍:复旦大学邱锡鹏老师编写的神经网络与深度学习讲义,ppt.
介绍:微软亚洲研究院开源分布式机器学习工具包.
介绍:语音识别的技术原理浅析
介绍:迈克尔·I.乔丹的主页.根据主页可以找到很多资源。迈克尔·I.乔丹是知名的计算机科学和统计学学者,主要研究机器学习和人工智能。他的重要贡献包括指出了机器学习与统计学之间的联系,并推动机器学习界广泛认识到贝叶斯网络的重要性。
介绍:杰弗里·埃弗里斯特·辛顿 FRS是一位英国出生的计算机学家和心理学家,以其在神经网络方面的贡献闻名。辛顿是反向传播算法和对比散度算法的发明人之一,也是深度学习的积极推动者.通过他的主页可以发掘到很多Paper以及优秀学生的paper,此外推荐他的学生Yann Lecun主页
介绍:Yoshua Bengio是机器学习方向的牛人,如果你不知道可以阅读对话机器学习大神Yoshua Bengio(上),对话机器学习大神Yoshua Bengio(下)
介绍:google大规模深度学习应用演进
介绍:MIT出版的深度学习电子书,公开电子书
介绍:深度卷积神经网络(CNN)提取特征的数学理论
介绍:推荐微软亚洲研究院何恺明主页
介绍:《语音与语言处理》第三版(草稿)
介绍:Stanford新课”计算词汇语义学”
介绍:上海交大张志华老师的统计机器学习与机器学习导论视频链接:密码: r9ak .概率基础
介绍:computational linguistics and deep learning视频,推荐Deep Learning: An Introduction from the NLP Perspective
介绍:(BlackHat2015)深度学习应用之流量鉴别(协议鉴别/异常检测),)(https://www.blackhat.com/docs/us-15/materials/us-15-Wang-The-Applications-Of-Deep-Learning-On-Traffic-Identification.pdf),[material](https://www.blackhat.com/docs/us-15/materials/us-15-Wang-The-Applications-Of-Deep-Learning-On-Traffic-Identification-wp.pdf)
介绍:一个推荐系统的Java库
介绍:多中心图的谱分解及其在网络入侵检测中的应用(MC-GPCA&MC-GDL)
介绍:用Python学计算统计学
介绍:datumbox-framework——Java的开源机器学习框架,该框架重点是提供大量的机器学习算法和统计检验,并能够处理中小规模的数据集
介绍:递归神经网络awesome系列,涵盖了书籍,项目,paper等
介绍:Pedro Domingos是华盛顿大学的教授,主要研究方向是机器学习与数据挖掘.在2015年的ACM webinar会议,曾发表了关于盘点机器学习领域的五大流派主题演讲.他的个人主页拥有很多相关研究的paper以及他的教授课程.
介绍:机器学习视频集锦
介绍:深度机器学习库与框架
介绍:这篇文章内的推荐系统资源很丰富,作者很有心,摘录了《推荐系统实战》内引用的论文.
介绍:(天文学)贝叶斯方法/MCMC教程——统计实战
介绍:免费书:统计稀疏学习,作者Trevor Hastie与Rob Tibshirani都是斯坦福大学的教授,Trevor Hastie更是在统计学学习上建树很多
介绍:R分布式计算的进化,此外推荐(R)气候变化可视化,(R)马尔可夫链入门
介绍:Nervana Systems在Startup.ML的主题研讨会——情感分析与深度强化学习
介绍:深度学习卷积概念详解.
介绍:Python推荐系统开发库汇总.
介绍:超棒的神经网络课程,深入浅出介绍深度学习,由Hugo Larochelle(Yoshua Bengio的博士生,Geoffrey Hinton之前的博士后)主讲,强烈推荐.
介绍:斯坦福新课程,面向视觉识别的卷积神经网络(Fei-Fei Li & Andrej Karpathy),slides+video,homework.
介绍:NIPS 2015会议总结第一部分,第二部分.
介绍:python机器学习入门资料梳理.
介绍:牛津大学著名视觉几何组VGG在IJCV16年首卷首期: Reading Text in the Wild with Convolutional Neural Networks,Jaderberg。这篇期刊文章融合了之前两篇会议(ECCV14,NIPS14ws),定位和识别图片中的文本(叫text spotting)。 端到端系统: 检测Region + 识别CNN。论文、数据和代码.
介绍:计算机视觉的一个较大的数据集索引, 包含387个标签,共收录了314个数据集合,点击标签云就可以找到自己需要的库了.
介绍:Tombone 对 ICCV SLAM workshop 的总结: the future of SLAM, SLAM vs deep learning 重点介绍了 monoSLAM 和 LSD-SLAM,而且讨论了 feature-based 和 feature-free method 的长短。在全民deep learning做visual perception的时候,再来读读CV中的 geometry.
介绍:Nervana Systems的开源深度学习框架neon发布.
介绍:ICCV 2015的ImageNet比赛以及MS COCO竞赛联合研讨会的幻灯片和视频.
介绍:Python机器学习入门.
介绍:Neural Enquirer 第二版.
介绍:[Google]基于TensorFlow的深度学习/机器学习课程.
介绍:R-bloggers网站2015″必读”的100篇文章,R语言学习的福音.
介绍:推荐书籍:<机器学习:概率视角>,样章Undirected graphical models Markov random fields.
介绍:这是一本在线的深度学习书籍,合著者有Ian Goodfellow, Yoshua Bengio 和 Aaron Courville.如果你是一位新入门的学员可以先看这本书籍Yoshua Bengio: How can one get started with machine learning?
介绍:UFLDL推荐的深度学习阅读列表.
介绍:纽约州立大学布法罗分校2015年春季机器学习课程主页.
介绍: Theano是主流的深度学习Python库之一,亦支持GPU,入门比较难.推荐Theano tutorial,Document
介绍:博士论文:神经网络统计语言模型.
介绍:用RNN预测像素,可以把被遮挡的图片补充完整.
介绍:微软研究院把其深度学习工具包CNTK,想进一步了解和学习CNTK的同学可以看前几天公布的《CNTK白皮书》An Introduction to Computational Networks and the Computational Network Toolkit.
介绍: 卡尔曼滤波器教材,用尽量少的数学和推导,传授直觉和经验,全部Python示例,内容覆盖卡尔曼滤波器、扩展卡尔曼滤波,无迹卡尔曼滤波等,包括练习和参考答案
介绍:在线免费书:面向数据科学的统计推断,R示例代码,很不错GitHub.
介绍:这本书是由Yoshua Bengio撰写的教程,其内容包含了学习人工智能所使用的深度学习架构的学习资源,书中的项目已停止更新DeepLearnToolbox.
介绍:这是一份机器学习和深度学习教程,文章和资源的清单。这张清单根据各个主题进行撰写,包括了许多与深度学习有关的类别、计算机视觉、加强学习以及各种架构.
介绍:这是由Donne Martin策划收集的IPython笔记本。话题涵盖大数据、Hadoop、scikit-learn和科学Python堆栈以及很多其他方面的内容。 至于深度学习,像是TensorFlow、Theano和Caffe之类的框架也均被涵盖其中,当然还有相关的特定构架和概念等.
介绍:开源的深度学习服务,DeepDetect是C++实现的基于外部机器学习/深度学习库(目前是Caffe)的API。给出了图片训练(ILSVRC)和文本训练(基于字的情感分析,NIPS15)的样例,以及根据图片标签索引到ElasticSearch中github.
介绍:这是国外的一个科技频道,涵盖了数据挖掘,分析以及数据科学类的文章.偶尔还有机器学习精选.
介绍:经典论文:数据挖掘与统计学.
介绍:NIPS’2015 Tutorial by Yoshua Bengio.
介绍:Nervana Systems的开源深度学习框架neon发布.
介绍:犹他州大学Matt Might教授推荐的研究生阅读清单.
介绍:开放数据集.
介绍:(edX)不确定性的科学——概率论导论(MITx).
介绍:R语言开发常用软件/工具推荐.
介绍:动态记忆网络实现.
介绍:英文主页
介绍:50个大数据分析最佳学习资源(课程、博客、教程等)
介绍:深度学习的全面硬件指南,从GPU到RAM、CPU、SSD、PCIe,译文
介绍:kaiming开源作品
介绍:自然语言处理(NLP)权威指南
介绍:如何在社会媒体上做语言检测?没有数据怎么办?推特官方公布了一个十分难得的数据集:12万标注过的Tweets,有70种语言
介绍:深度学习和机器学习重要会议ICLR 2016录取文章
介绍:机器学习——深度非技术指南
介绍:数据叙事入门指南——创意生成/数据采集/内容设计相关资源推荐
介绍:WikiTableQuestions——复杂真实问答数据集
介绍:(2016版)35个超棒的免费大数据源
介绍:Ion Stoica和 Michael I. Jordan两位大家首次联手发文,CAFFE和SPARK完美结合,分布式深度学习混搭模式!github
介绍:深度学习(分类)文献集
介绍:深度学习阅读列表
介绍:探索R包的好网站Awesome 42
介绍:MLbase是Prof. Dr. Tim Kraska的一个研究项目,MLbase是一个分布式机器学习管理系统
介绍:分布式深度学习平台SINGA介绍
介绍:Spark视频集锦
介绍:R语言深度学习第一节:从零开始
介绍:图解机器学习
介绍:AMiner论文引用数据集(v7:2,244,021 papers and 4,354,534 citation relationships)
介绍:10本最佳机器学习免费书
介绍:ICCV15视频集
介绍::(Yahoo)基于Hadoop/Spark的分布式Caffe实现CaffeOnSpark
介绍:Learning to Rank简介
介绍:全球深度学习专家列表,涵盖研究者主页
介绍:ACM IUI’16论文集Conference Navigator – Proceedings
介绍:Nando de Freitas在 Oxford 开设的深度学习课程,课程youtube地址,Google DeepMind的研究科学家,此外首页:computervisiontalks的内容也很丰富,如果你是做机器视觉方面的研究,推荐也看看其他内容.肯定收获也不小.还有,这位youtube主页顶过的视频也很有份量
介绍:Geoffrey Hinton在Coursera开设的MOOC
介绍:深度学习领域的Hacker news.紧跟深度学习的新闻、研究进展和相关的创业项目。从事机器学习,深度学习领域的朋友建议每天看一看
介绍:Maxout网络剖析
介绍:NIPS领域的会议paper集锦
介绍:机器学习在生物工程领域的应用,如果你从事生物工程领域,可以先阅读一篇文章详细介绍
介绍:深度学习在生物信息学领域的应用
介绍:一些关于机器学习需要知道知识,对于刚刚入门机器学习的同学应该读一读
介绍:剑桥大学机器学习用户组主页,网罗了剑桥大学一些机器学习领域专家与新闻
介绍:Randy Olson’s的一些数据分析与机器学习项目库,是学习实践的好材料
介绍:Golang机器学习库,简单,易扩展
介绍:用Swift开发苹果应用的倒是很多,而用来做机器学习的就比较少了.Swift Ai在这方面做了很多聚集.可以看看
介绍:如何向一位5岁的小朋友解释支持向量机(SVM)
介绍: reddit的机器学习栏目
介绍: 计算机视觉领域的一些牛人博客,超有实力的研究机构等的网站链接.做计算机视觉方向的朋友建议多关注里面的资源
介绍:香港中文大学深度学习研究主页,此外研究小组对2013年deep learning 的最新进展和相关论文做了整理,其中useful links的内容很受益
介绍: 这是一篇关于搜索引擎的博士论文,对现在普遍使用的搜索引擎google,bing等做了分析.对于做搜索类产品的很有技术参考价值
介绍: 深度学习书籍推荐(毕竟这类书比较少).
介绍: 深度学习书籍推荐(毕竟这类书比较少).
介绍: 贝叶斯定理在深度学习方面的研究论文.
介绍: 来自谷歌大脑的重温分布式梯度下降.同时推荐大规模分布式深度网络
介绍: 社交计算研究相关问题综述.
介绍: 社交计算应用领域概览,里面有些经典论文推荐
介绍: 协同过滤在推荐系统应用.
介绍: 协同过滤在内容推荐的研究.
介绍: 协同过滤经典论文.
介绍: 协同过滤算法.
介绍: 亚马逊对于协同过滤算法应用.
介绍: 协同过滤的隐式反馈数据集处理.
介绍: 计算机图形,几何等论文,教程,代码.做计算机图形的推荐收藏.
介绍: 推荐哥伦比亚大学课程,稀疏表示和高维几何.12年由Elsevier、13年至今由PAMI(仍由Elsevier赞助)设立的青年研究者奖 (Young Researcher Award)授予完成博士学位后七年内取得杰出贡献的;由CV社区提名,在CVPR会议上宣布。2015年得主是哥大助理教授John Wright,09年《健壮人脸识别的稀疏表示法》引用已超5K.
介绍: CMU机器学习系著名教授Alex Smola在Quora对于《程序员如何学习Machine Learning》的建议:Alex推荐了不少关于线性代数、优化、系统、和统计领域的经典教材和资料.
介绍: 书籍推荐,深度学习基础.源码
介绍: 软件工程领域现在也对机器学习和自然语言处理很感兴趣,有人推出了“大代码”的概念,分享了不少代码集合,并且觉得ML可以用在预测代码Bug,预测软件行为,自动写新代码等任务上。大代码数据集下载
介绍: 深度学习进行目标识别的资源列表:包括RNN、MultiBox、SPP-Net、DeepID-Net、Fast R-CNN、DeepBox、MR-CNN、Faster R-CNN、YOLO、DenseBox、SSD、Inside-Outside Net、G-CNN
介绍: Yann LeCun 2016深度学习课程的幻灯片(Deep Learning Course by Yann LeCun at Collège de France 2016)百度云密码: cwsm 原地址
介绍: 斯坦福人机交互组五篇CHI16文章。1.众包激励机制的行为经济学研究:批量结算比单任务的完成率高。2.在众包专家和新手间建立联系:微实习。3.词 嵌入结合众包验证的词汇主题分类(如猫、狗属于宠物)。4.词嵌入结合目标识别的活动预测。5.鼓励出错以加快众包速度。
介绍: 自学数据科学
介绍: 本课是CS224D一节介绍TensorFlow课程,ppt,DeepDreaming with TensorFlow
介绍: Leaf是一款机器学习的开源框架,专为黑客打造,而非为科学家而作。它用Rust开发,传统的机器学习,现今的深度学习通吃。Leaf
介绍: GTC 2016视频,MXnet的手把手深度学习tutorial,相关参考资料MXNet Tutorial for NVidia GTC 2016.
介绍: OpenAI Gym:开发、比较强化学习算法工具箱
介绍: 机器学习会议ICLR 2016 论文的代码集合
介绍: 此书是斯坦福大学概率图模型大牛Daphne Koller所写,主要涉及的是贝叶斯网络和马尔科夫逻辑网络的learning和inference问题,同时又对PGM有深刻的理论解释,是学习概率图模型必看的书籍。难度中上,适合有一些ML基础的研究生.备份地址
介绍: 此书是剑桥大学著名信息论专家David MacKay所写,出发角度与很多机器学习的书籍都不一样,inference和MCMC那章写的最好,难度中。适合研究生和本科生。
介绍: 非常好的Convex Optimization教材,覆盖了各种constrained和unconstrained optimization方法,介绍了convex优化的基本概念和理论。难度中,适合对优化和机器学习有一定基础的人群
介绍: 本书是CMU机器学习系主任Mitchell早年写的机器学习教科书,年代有点久远.难度不高。适合初学者,本科生,研究生
介绍: 本书设计学习Kernel和SVM的各种理论基础,需要较强的数学功底,适合对kernel和SVM感兴趣的同学选读Learning with Kernels PPT,参考Learning with Kernels
介绍: 斯坦福统计系三位大神的统计学习教科书,偏统计和学习理论,需要对线性代数、统计和概率论有一定基础、难度高、适合研究生
介绍: 本书是著名机器学习工具Weka作者撰写的应用机器学习指导书、非常实用、难度低、适合文科和各种应用科学做参考
介绍: 本书也是一本比较受欢迎的NLP教科书,难度一般,主要覆盖统计NLP方法,是斯坦福的另一位大牛Chirs manning所写
介绍: 在北美NLP最常用的教材,斯坦福Jurafsky所写的自然语言处理入门教程,覆盖面较为全面,难度中低。适合本科生和研究生
介绍: 实战型教程,著名工具NLTK作者的著作,适合本科生和入门者边动手边学
机器学习(Machine Learning)&深度学习(Deep Learning)资料(Chapter 1)
by ty4z2008 (廖君)
Source: https://github.com/ty4z2008/Qix/blob/master/dl.md
介绍:这是一篇介绍机器学习历史的文章,介绍很全面,从感知机、神经网络、决策树、SVM、Adaboost到随机森林、Deep Learning.
介绍:这是瑞士人工智能实验室Jurgen Schmidhuber写的最新版本《神经网络与深度学习综述》本综述的特点是以时间排序,从1940年开始讲起,到60-80年代,80-90年代,一 直讲到2000年后及最近几年的进展。涵盖了deep learning里各种tricks,引用非常全面.
介绍:这是一份python机器学习库,如果您是一位python工程师而且想深入的学习机器学习.那么这篇文章或许能够帮助到你.
介绍:这一篇介绍如果设计和管理属于你自己的机器学习项目的文章,里面提供了管理模版、数据管理与实践方法.
介绍:如果你还不知道什么是机器学习,或则是刚刚学习感觉到很枯燥乏味。那么推荐一读。这篇文章已经被翻译成中文,如果有兴趣可以移步http://blog.jobbole.com/67616/
介绍:R语言是机器学习的主要语言,有很多的朋友想学习R语言,但是总是忘记一些函数与关键字的含义。那么这篇文章或许能够帮助到你
介绍:我该如何选择机器学习算法,这篇文章比较直观的比较了Naive Bayes,Logistic Regression,SVM,决策树等方法的优劣,另外讨论了样本大小、Feature与Model权衡等问题。此外还有已经翻译了的版本:http://www.52ml.net/15063.html
介绍:深度学习概述:从感知机到深度网络,作者对于例子的选择、理论的介绍都很到位,由浅入深。翻译版本:http://www.cnblogs.com/xiaowanyer/p/3701944.html
- 《The LION Way: Machine Learning plus Intelligent Optimization》
介绍:<机器学习与优化>这是一本机器学习的小册子, 短短300多页道尽机器学习的方方面面. 图文并茂, 生动易懂, 没有一坨坨公式的烦恼. 适合新手入门打基础, 也适合老手温故而知新. 比起MLAPP/PRML等大部头, 也许这本你更需要!具体内容推荐阅读:http://intelligent-optimization.org/LIONbook/
- 《深度学习与统计学习理论》
介绍:作者是来自百度,不过他本人已经在2014年4月份申请离职了。但是这篇文章很不错如果你不知道深度学习与支持向量机/统计学习理论有什么联系?那么应该立即看看这篇文章.
介绍:这本书是由谷歌公司和MIT共同出品的计算机科学中的数学:Mathematics for Computer Science,Eric Lehman et al 2013 。分为5大部分:1)证明,归纳。2)结构,数论,图。3)计数,求和,生成函数。4)概率,随机行走。5)递归。等等
介绍:信息时代的计算机科学理论,目前国内有纸质书购买,iTunes购买
介绍:这是一本由雪城大学新编的第二版《数据科学入门》教材:偏实用型,浅显易懂,适合想学习R语言的同学选读。
介绍:这并不是一篇文档或书籍。这是篇向图灵奖得主Donald Knuth提问记录稿: 近日, Charles Leiserson, Al Aho, Jon Bentley等大神向Knuth提出了20个问题,内容包括TAOCP,P/NP问题,图灵机,逻辑,以及为什么大神不用电邮等等。
介绍:不会统计怎么办?不知道如何选择合适的统计模型怎么办?那这篇文章你的好好读一读了麻省理工Joshua B. Tenenbaum和剑桥Zoubin Ghahramani合作,写了一篇关于automatic statistician的文章。可以自动选择回归模型类别,还能自动写报告…
介绍:对深度学习和representation learning最新进展有兴趣的同学可以了解一下
介绍:这是一本信息检索相关的书籍,是由斯坦福Manning与谷歌副总裁Raghavan等合著的Introduction to Information Retrieval一直是北美最受欢迎的信息检索教材之一。最近作者增加了该课程的幻灯片和作业。IR相关资源:http://www-nlp.stanford.edu/IR-book/information-retrieval.html
介绍:Deniz Yuret用10张漂亮的图来解释机器学习重要概念:1. Bias/Variance Tradeoff 2. Overfitting 3. Bayesian / Occam’s razor 4. Feature combination 5. Irrelevant feature 6. Basis function 7. Discriminative / Generative 8. Loss function 9. Least squares 10. Sparsity.很清晰
介绍:雅虎研究院的数据集汇总: 包括语言类数据,图与社交类数据,评分与分类数据,计算广告学数据,图像数据,竞赛数据,以及系统类的数据。
介绍:这是一本斯坦福统计学著名教授Trevor Hastie和Robert Tibshirani的新书,并且在2014年一月已经开课:https://class.stanford.edu/courses/HumanitiesScience/StatLearning/Winter2014/about
介绍:机器学习最佳入门学习资料汇总是专为机器学习初学者推荐的优质学习资源,帮助初学者快速入门。而且这篇文章的介绍已经被翻译成中文版。如果你不怎么熟悉,那么我建议你先看一看中文的介绍。
介绍:主要是顺着Bengio的PAMI review的文章找出来的。包括几本综述文章,将近100篇论文,各位山头们的Presentation。全部都可以在google上找到。
介绍:这是一本书籍,主要介绍的是跨语言信息检索方面的知识。理论很多
介绍:本文共有三个系列,作者是来自IBM的工程师。它主要介绍了推荐引擎相关算法,并帮助读者高效的实现这些算法。 探索推荐引擎内部的秘密,第 2 部分: 深度推荐引擎相关算法 – 协同过滤,探索推荐引擎内部的秘密,第 3 部分: 深度推荐引擎相关算法 – 聚类
介绍:康奈尔大学信息科学系助理教授David Mimno写的《对机器学习初学者的一点建议》, 写的挺实际,强调实践与理论结合,最后还引用了冯 • 诺依曼的名言: “Young man, in mathematics you don’t understand things. You just get used to them.”
介绍:这是一本关于分布式并行处理的数据《Explorations in Parallel Distributed Processing: A Handbook of Models, Programs, and Exercises》,作者是斯坦福的James L. McClelland。着重介绍了各种神级网络算法的分布式实现,做Distributed Deep Learning 的童鞋可以参考下
介绍:【“机器学习”是什么?】John Platt是微软研究院杰出科学家,17年来他一直在机器学习领域耕耘。近年来机器学习变得炙手可热,Platt和同事们遂决定开设博客,向公众介绍机器学习的研究进展。机器学习是什么,被应用在哪里?来看Platt的这篇博文
介绍:2014年国际机器学习大会(ICML)已经于6月21-26日在国家会议中心隆重举办。本次大会由微软亚洲研究院和清华大学联手主办,是这 个有着30多年历史并享誉世界的机器学习领域的盛会首次来到中国,已成功吸引海内外1200多位学者的报名参与。干货很多,值得深入学习下
介绍:这篇文章主要是以Learning to Rank为例说明企业界机器学习的具体应用,RankNet对NDCG之类不敏感,加入NDCG因素后变成了LambdaRank,同样的思想从神经网络 改为应用到Boosted Tree模型就成就了LambdaMART。Chirs Burges,微软的机器学习大神,Yahoo 2010 Learning to Rank Challenge第一名得主,排序模型方面有RankNet,LambdaRank,LambdaMART,尤其以LambdaMART最为突出,代表论文为: From RankNet to LambdaRank to LambdaMART: An Overview 此外,Burges还有很多有名的代表作,比如:A Tutorial on Support Vector Machines for Pattern Recognition
Some Notes on Applied Mathematics for Machine Learning
介绍:100 Best GitHub: Deep Learning
介绍:本教程将阐述无监督特征学习和深度学习的主要观点。通过学习,你也将实现多个功能学习/深度学习算法,能看到它们为你工作,并学习如何应用 /适应这些想法到新问题上。本教程假定机器学习的基本知识(特别是熟悉的监督学习,逻辑回归,梯度下降的想法),如果你不熟悉这些想法,我们建议你去这里机器学习课程,并先完成第II,III,IV章(到逻辑回归)。此外这关于这套教程的源代码在github上面已经有python版本了 UFLDL Tutorial Code
*《Deep Learning for Natural Language Processing and Related Applications》
介绍:这份文档来自微软研究院,精髓很多。如果需要完全理解,需要一定的机器学习基础。不过有些地方会让人眼前一亮,毛塞顿开。
介绍:这是一篇介绍图像卷积运算的文章,讲的已经算比较详细的了
介绍:每天请一个大牛来讲座,主要涉及机器学习,大数据分析,并行计算以及人脑研究。https://www.youtube.com/user/smolix (需翻墙)
介绍:一个超级完整的机器学习开源库总结,如果你认为这个碉堡了,那后面这个列表会更让你惊讶:【Awesome Awesomeness】,国内已经有热心的朋友进行了翻译中文介绍,机器学习数据挖掘免费电子书
介绍:ACL候任主席、斯坦福大学计算机系Chris Manning教授的《自然语言处理》课程所有视频已经可以在斯坦福公开课网站上观看了(如Chrome不行,可用IE观看) 作业与测验也可以下载。
介绍:对比 Deep Learning 和 Shallow Learning 的好文,来着浙大毕业、MIT 读博的 Chiyuan Zhang 的博客。
介绍:利用卷积神经网络做音乐推荐。
介绍:神经网络的免费在线书,已经写了三章了,还有对应的开源代码:https://github.com/mnielsen/neural-networks-and-deep-learning 爱好者的福音。
介绍:Java机器学习相关平台和开源的机器学习库,按照大数据、NLP、计算机视觉和Deep Learning分类进行了整理。看起来挺全的,Java爱好者值得收藏。
介绍:机器学习最基本的入门文章,适合零基础者
介绍:机器学习的算法很多。很多时候困惑人们都是,很多算法是一类算法,而有些算法又是从其他算法中延伸出来的。这里,我们从两个方面来给大家介绍,第一个方面是学习的方式,第二个方面是算法的类似性。
介绍:看题目你已经知道了是什么内容,没错。里面有很多经典的机器学习论文值得仔细与反复的阅读。
介绍:视频由加州理工学院(Caltech)出品。需要英语底子。
介绍:总结了机器学习的经典书籍,包括数学基础和算法理论的书籍,可做为入门参考书单。
介绍:16本机器学习的电子书,可以下载下来在pad,手机上面任意时刻去阅读。不多我建议你看完一本再下载一本。
介绍:标题很大,从新手到专家。不过看完上面所有资料。肯定是专家了
介绍:入门的书真的很多,而且我已经帮你找齐了。
介绍:Sibyl 是一个监督式机器学习系统,用来解决预测方面的问题,比如 YouTube 的视频推荐。
介绍:关于(Deep) Neural Networks在 NLP 和 Text Mining 方面一些paper的总结
介绍:计算机视觉入门之前景目标检测1(总结)
介绍:计算机视觉入门之行人检测
介绍:Important resources for learning and understanding . Is awesome
介绍:这又是一篇机器学习初学者的入门文章。值得一读
介绍:在线Neural Networks and Deep Learning电子书
介绍:python的17个关于机器学习的工具
介绍:下集在这里神奇的伽玛函数(下)
介绍:作者王益目前是腾讯广告算法总监,王益博士毕业后在google任研究。这篇文章王益博士7年来从谷歌到腾讯对于分布机器学习的所见所闻。值得细读
介绍:把机器学习提升的级别分为0~4级,每级需要学习的教材和掌握的知识。这样,给机器学习者提供一个上进的路线图,以免走弯路。另外,整个网站都是关于机器学习的,资源很丰富。
介绍:机器学习各个方向综述的网站
介绍:深度学习阅资源列表
介绍:这是一本来自微的研究员 li Peng和Dong Yu所著的关于深度学习的方法和应用的电子书
介绍:2014年七月CMU举办的机器学习夏季课刚刚结束 有近50小时的视频、十多个PDF版幻灯片,覆盖 深度学习,贝叶斯,分布式机器学习,伸缩性 等热点话题。所有13名讲师都是牛人:包括大牛Tom Mitchell (他的[机器学习]是名校的常用教材),还有CMU李沐 .(1080P高清哟)
介绍:在今年的IEEE/IFIP可靠系统和网络(DSN)国际会议上,Google软件工程师Tushar Chandra做了一个关于Sibyl系统的主题演讲。 Sibyl是一个监督式机器学习系统,用来解决预测方面的问题,比如YouTube的视频推荐。详情请阅读google sibyl
介绍:谷歌研究院的Christian Szegedy在谷歌研究院的博客上简要地介绍了他们今年参加ImageNet取得好成绩的GoogLeNet系统.是关于图像处理的。
介绍:贝叶斯学习。如果不是很清可看看概率编程语言与贝叶斯方法实践
介绍:网友问伯克利机器学习大牛、美国双料院士Michael I. Jordan:”如果你有10亿美金,你怎么花?Jordan: “我会用这10亿美金建造一个NASA级别的自然语言处理研究项目。”
介绍:常见面试之机器学习算法思想简单梳理,此外作者还有一些其他的机器学习与数据挖掘文章和深度学习文章,不仅是理论还有源码。
介绍:Videolectures上最受欢迎的25个文本与数据挖掘视频汇总
介绍:在Kaggle上经常取得不错成绩的Tim Dettmers介绍了他自己是怎么选择深度学习的GPUs, 以及个人如何构建深度学习的GPU集群: http://t.cn/RhpuD1G
介绍:对话机器学习大神Michael Jordan
介绍:还有2,3部分。http://blog.sina.com.cn/s/blog_46d0a3930101gs5h.html
介绍:是Stanford 教授 Andrew Ng 的 Deep Learning 教程,国内的机器学习爱好者很热心的把这个教程翻译成了中文。如果你英语不好,可以看看这个
介绍:因为近两年来,深度学习在媒体界被炒作很厉害(就像大数据)。其实很多人都还不知道什么是深度学习。这篇文章由浅入深。告诉你深度学究竟是什么!
介绍:这是斯坦福大学做的一免费课程(很勉强),这个可以给你在深度学习的路上给你一个学习的思路。里面提到了一些基本的算法。而且告诉你如何去应用到实际环境中。中文版
介绍:这是多伦多大学做的一个深度学习用来识别图片标签/图转文字的demo。是一个实际应用案例。有源码
介绍:机器学习模型,阅读这个内容需要有一定的基础。
介绍: (CRAN Task Views, 34种常见任务,每个任务又各自分类列举若干常用相关工具包) 例如: 机器学习,自然语言处理,时间序列分析,空间信息分析,多重变量分析,计量经济学,心理统计学,社会学统计,化学计量学,环境科学,药物代谢动力学 等
介绍: 机器学习无疑是当前数据分析领域的一个热点内容。很多人在平时的工作中都或多或少会用到机器学习的算法。本文为您总结一下常见的机器学习算法,以供您在工作和学习中参考.
介绍: 很多干货,而且作者还总结了好几个系列。另外还作者还了一个文章导航.非常的感谢作者总结。
Deep Learning(深度学习)学习笔记整理系列之(二)
Deep Learning(深度学习)学习笔记整理系列之(三)
Deep Learning(深度学习)学习笔记整理系列之(四)
Deep Learning(深度学习)学习笔记整理系列之(五)
Deep Learning(深度学习)学习笔记整理系列之(六)
Deep Learning(深度学习)学习笔记整理系列之(七)
DeepLearning(深度学习)学习笔记整理系列之(八)
介绍:传送理由:Rob Fergus的用深度学习做计算机是觉的NIPS 2013教程。有mp4, mp3, pdf各种下载 他是纽约大学教授,目前也在Facebook工作,他2014年的8篇论文
介绍:FudanNLP,这是一个复旦大学计算机学院开发的开源中文自然语言处理(NLP)工具包 Fudan NLP里包含中文分词、关键词抽取、命名实体识别、词性标注、时间词抽取、语法分析等功能,对搜索引擎 文本分析等极为有价值。
介绍:LinkedIn 开源的机器学习工具包,支持单机, Hadoop cluster,和 Spark cluster 重点是 logistic regression 算法
介绍:对于英语不好,但又很想学习机器学习的朋友。是一个大的福利。机器学习周刊目前主要提供中文版,还是面向广大国内爱好者,内容涉及机器学习、数据挖掘、并行系统、图像识别、人工智能、机器人等等。谢谢作者
介绍:《线性代数》是《机器学习》的重要数学先导课程。其实《线代》这门课讲得浅显易懂特别不容易,如果一上来就讲逆序数及罗列行列式性质,很容易让学生失去学习的兴趣。我个人推荐的最佳《线性代数》课程是麻省理工Gilbert Strang教授的课程。 课程主页
介绍:大数据数据处理资源、工具不完备列表,从框架、分布式编程、分布式文件系统、键值数据模型、图数据模型、数据可视化、列存储、机器学习等。很赞的资源汇总。
介绍:雅虎邀请了一名来自本古里安大学的访问学者,制作了一套关于机器学习的系列视频课程。本课程共分为7期,详细讲解了有关SVM, boosting, nearest neighbors, decision trees 等常规机器学习算法的理论基础知识。
介绍:应对大数据时代,量子机器学习的第一个实验 paper 下载
介绍:Wired杂志报道了UCLA数学博士Chris McKinlay (图1)通过大数据手段+机器学习方法破解婚恋网站配对算法找到真爱的故事,通过Python脚本控制着12个账号,下载了婚恋网站2万女用户的600万 问题答案,对他们进行了统计抽样及聚类分析(图2,3),最后终于收获了真爱。科技改变命运!
介绍:MIT的Underactuated Robotics于 2014年10月1日开课,该课属于MIT研究生级别的课程,对机器人和非线性动力系统感兴趣的朋友不妨可以挑战一下这门课程!
介绍:mllib实践经验分享
介绍:Google用Deep Learning做的antispam(反垃圾邮件)
介绍:NLP常用信息资源* 《NLP常用信息资源》
介绍:机器学习速查表
介绍:从1996年开始在计算机科学的论文中被引用次数最多的论文
介绍:把今年的一个ACM Trans. on Graphics (TOG)论文中的代码整理为一个开源的算法框架,共享出来了。欢迎大家使用。可以实时的采集3D数据、重建出三维模型。Online learning,GPU Random forest,GPU CRF也会后续公开。
介绍:【神经网络黑客指南】现在,最火莫过于深度学习(Deep Learning),怎样更好学习它?可以让你在浏览器中,跑起深度学习效果的超酷开源项目ConvNetJS作者karpathy告诉你,最佳技巧是,当你开始写代码,一切将变得清晰。他刚发布了一本图书,不断在线更新
介绍:前Google广告系统工程师Josh Wills 讲述工业界和学术界机器学习的异同,大实话
介绍:使用Neo4j 做电影评论的情感分析。
介绍:不仅是资料,而且还对有些资料做了注释。
介绍:深度学习入门的初级读本
介绍:机器学习教会了我们什么?
介绍:scikit-learn是在SciPy基础上构建的用于机器学习的Python模块。
介绍:乔丹教授(Michael I. Jordan)教授是机器学习领域神经网络的大牛,他对深度学习、神经网络有着很浓厚的兴趣。因此,很多提问的问题中包含了机器学习领域的各类模型,乔丹教授对此一一做了解释和展望。
介绍:A*搜索是人工智能基本算法,用于高效地搜索图中两点的最佳路径, 核心是 g(n)+h(n): g(n)是从起点到顶点n的实际代价,h(n)是顶点n到目标顶点的估算代价。合集
介绍:本项目利用了Microsoft Azure,可以在几分种内完成NLP on Azure Website的部署,立即开始对FNLP各种特性的试用,或者以REST API的形式调用FNLP的语言分析功能
介绍:现任复旦大学首席教授、计算机软件博士生导师。计算机科学研究所副所长.内部课程
介绍:好东西的干货真的很多
介绍:从硬件、图像到健康、生物、大数据、生物信息再到量子计算等,Amund Tveit等维护了一个DeepLearning.University小项目:收集从2014年开始深度学习文献,相信可以作为深度学习的起点,github
介绍:EMNLP上两篇关于stock trend 用到了deep model组织特征; Exploiting Social Relations and Sentiment for Stock Prediction用到了stock network。
介绍:作者是深度学习一线大牛Bengio组写的教程,算法深入显出,还有实现代码,一步步展开。
介绍:许多传统的机器学习任务都是在学习function,不过谷歌目前有开始学习算法的趋势。谷歌另外的这篇学习Python程序的Learning to Execute也有相似之处
介绍:作者是华为技术有限公司,诺亚方舟实验室,首席科学家的李航博士写的关于信息检索与自然语言处理的文章
介绍:利用机用器学习在谣言的判别上的应用,此外还有两个。一个是识别垃圾与虚假信息的paper.还有一个是网络舆情及其分析技术
介绍:该课程是网易公开课的收费课程,不贵,超级便宜。主要适合于对利用R语言进行机器学习,数据挖掘感兴趣的人。
介绍:本章中作者总结了三代机器学习算法实现的演化:第一代非分布式的, 第二代工具如Mahout和Rapidminer实现基于Hadoop的扩展,第三代如Spark和Storm实现了实时和迭代数据处理。BIG DATA ANALYTICS BEYOND HADOOP
介绍:讲计算机视觉的四部奇书(应该叫经典吧)之一,另外三本是Hartley的《多图几何》、Gonzalez的《数字图像处理》、Rafael C.Gonzalez / Richard E.Woods 的《数字图像处理》
介绍:里面基本没涉及到具体算法,但作者介绍了CF在LinkedIn的很多应用,以及他们在做推荐过程中获得的一些经验。最后一条经验是应该监控log数据的质量,因为推荐的质量很依赖数据的质量!
介绍:初学者如何查阅自然语言处理(NLP)领域学术资料
介绍:用树莓派和相机模块进行人脸识别
介绍:如何利用深度学习与大数据构建对话系统
介绍:Francis Bach合作的有关稀疏建模的新综述(书):Sparse Modeling for Image and Vision Processing,内容涉及Sparsity, Dictionary Learning, PCA, Matrix Factorization等理论,以及在图像和视觉上的应用,而且第一部分关于Why does the l1-norm induce sparsity的解释也很不错。
介绍:RKHS是机器学习中重要的概念,其在large margin分类器上的应用也是广为熟知的。如果没有较好的数学基础,直接理解RKHS可能会不易。本文从基本运算空间讲到Banach和Hilbert空间,深入浅出,一共才12页。
介绍:许多同学对于机器学习及深度学习的困惑在于,数学方面已经大致理解了,但是动起手来却不知道如何下手写代码。斯坦福深度学习博士Andrej Karpathy写了一篇实战版本的深度学习及机器学习教程,手把手教你用Javascript写神经网络和SVM.
介绍:【语料库】语料库资源汇总
介绍:本文会过一遍最流行的机器学习算法,大致了解哪些方法可用,很有帮助。
介绍:这个里面有很多关于机器学习、信号处理、计算机视觉、深入学习、神经网络等领域的大量源代码(或可执行代码)及相关论文。科研写论文的好资源
介绍:NYU 2014年的深度学习课程资料,有视频
介绍:计算机视觉数据集不完全汇总
介绍:机器学习开源软件
介绍:A Library for Support Vector Machines
介绍:数据挖掘十大经典算法之一
介绍:github上面100个非常棒的项目
介绍:当前加州大学欧文分校为机器学习社区维护着306个数据集。查询数据集
介绍:Andrej Karpathy 是斯坦福大学Li Fei-Fei的博士生,使用机器学习在图像、视频语义分析领域取得了科研和工程上的突破,发的文章不多,但每个都很扎实,在每一个问题上都做到了state-of-art.
介绍:Andrej Karpathy的深度强化学习演示,论文在这里
介绍:CIKM Cup(或者称为CIKM Competition)是ACM CIKM举办的国际数据挖掘竞赛的名称。
介绍:杰弗里·埃弗里斯特·辛顿 FRS是一位英国出生的计算机学家和心理学家,以其在神经网络方面的贡献闻名。辛顿是反向传播算法和对比散度算法的发明人之一,也是深度学习的积极推动者.
介绍:微软研究院深度学习技术中心在CIKM2014 上关于《自然语言处理的深度学习理论与实际》教学讲座的幻灯片
介绍: 本文基于<支持向量机的高频限价订单的动态建模>采用了 Apache Spark和Spark MLLib从纽约股票交易所的订单日志数据构建价格运动预测模型。(股票有风险,投资谨慎)GitHub源代码托管地址.
介绍:徐宗本 院士将于热爱机器学习的小伙伴一起探讨有关于机器学习的几个理论性问题,并给出一些有意义的结论。最后通过一些实例来说明这些理论问题的物理意义和实际应用价值。
介绍:作者还著有《这就是搜索引擎:核心技术详解》一书,主要是介绍应用层的东西
介绍:机器学习课程
介绍:人脸识别必读文章推荐
介绍:推荐系统经典论文文献
介绍:人脸识别必读文章推荐
介绍:第十二届中国”机器学习及其应用”研讨会PPT
介绍:统计学习是关于计算机基于数据构建的概率统计模型并运用模型对数据进行预测和分析的一门科学,统计学习也成为统计机器学习。课程来自上海交通大学
介绍:机器学习的目标是对计算机编程,以便使用样本数据或以往的经验来解决给定的问题.
介绍:CIKM 2014 Jeff Dean、Qi Lu、Gerhard Weikum的主题报告的幻灯片, Alex Smola、Limsoon Wong、Tong Zhang、Chih-Jen Lin的Industry Track报告的幻灯片
介绍:部分中文列表
介绍:此外作者还有一篇元算法、AdaBoost python实现文章
介绍:加州伯克利大学博士Aria Haghighi写了一篇超赞的数值优化博文,从牛顿法讲到拟牛顿法,再讲到BFGS以及L-BFGS, 图文并茂,还有伪代码。强烈推荐。
介绍:还有续集简明深度学习方法概述(二)
介绍:R语言程序员私人定制版
介绍:谷歌地图解密
介绍:空间数据挖掘常用方法
介绍:Kaggle新比赛 ”When bag of words meets bags of popcorn“ aka ”边学边用word2vec和deep learning做NLP“ 里面全套教程教一步一步用python和gensim包的word2vec模型,并在实际比赛里面比调参数和清数据。 如果已装过gensim不要忘升级
介绍:PyNLPIR提供了NLPIR/ICTCLAS汉语分词的Python接口,此外Zhon提供了常用汉字常量,如CJK字符和偏旁,中文标点,拼音,和汉字正则表达式(如找到文本中的繁体字)
介绍:这文章说把最近模型识别上的突破应用到围棋软件上,打16万张职业棋谱训练模型识别功能。想法不错。训练后目前能做到不用计算,只看棋盘就给 出下一步,大约10级棋力。但这篇文章太过乐观,说什么人类的最后一块堡垒马上就要跨掉了。话说得太早。不过,如果与别的软件结合应该还有潜力可挖。@万 精油墨绿
介绍:UT Austin教授Eric Price关于今年NIPS审稿实验的详细分析,他表示,根据这次实验的结果,如果今年NIPS重新审稿的话,会有一半的论文被拒。
介绍:KDNuggets分别总结了2014年14个阅读最多以及分享最多的文章。我们从中可以看到多个主题——深度学习,数据科学家职业,教育和薪酬,学习数据科学的工具比如R和Python以及大众投票的最受欢迎的数据科学和数据挖掘语言
介绍:Python实现线性回归,作者还有其他很棒的文章推荐可以看看
介绍:2014中国大数据技术大会33位核心专家演讲PDF下载
介绍:这是T. Mikolov & Y. Bengio最新论文Ensemble of Generative and Discriminative Techniques for Sentiment Analysis of Movie Reviews ,使用RNN和PV在情感分析效果不错,[项目代码](https://github.com/mesnilgr/iclr15)公布在github(目前是空的)。这意味着Paragraph Vector终于揭开面纱了嘛。
介绍:NLPIR/ICTCLAS2015分词系统发布与用户交流大会上的演讲,请更多朋友检阅新版分词吧。 我们实验室同学的演讲包括:孙梦姝-基于评论观点挖掘的商品搜索技术研究 李然-主题模型
介绍:Convex Neural Networks 解决维数灾难
介绍:介绍CNN参数在使用bp算法时该怎么训练,毕竟CNN中有卷积层和下采样层,虽然和MLP的bp算法本质上相同,但形式上还是有些区别的,很显然在完成CNN反向传播前了解bp算法是必须的。此外作者也做了一个资源集:机器学习,深度学习,视觉,数学等
介绍:如果要在一篇文章中匹配十万个关键词怎么办?Aho-Corasick 算法利用添加了返回边的Trie树,能够在线性时间内完成匹配。 但如果匹配十万个正则表达式呢 ? 这时候可以用到把多个正则优化成Trie树的方法,如日本人写的 Regexp::Trie
介绍:深度学习阅读清单
介绍:Caffe是一个开源的深度学习框架,作者目前在google工作,作者主页Yangqing Jia (贾扬清)
介绍:2014 ImageNet冠军GoogLeNet深度学习模型的Caffe复现模型,GoogleNet论文.
介绍:LambdaNetLambdaNet是由Haskell实现的一个开源的人工神经网络库,它抽象了网络创建、训练并使用了高阶函数。该库还提供了一组预定义函数,用户可以采取多种方式组合这些函数来操作现实世界数据。
介绍:如果你从事互联网搜索,在线广告,用户行为分析,图像识别,自然语言理解,或者生物信息学,智能机器人,金融预测,那么这门核心课程你必须深入了解。
介绍:”人工智能研究分许多流派。其中之一以IBM为代表,认为只要有高性能计算就可得到智能,他们的‘深蓝’击败了世界象棋冠军;另一流派认为智 能来自动物本能;还有个很强的流派认为只要找来专家,把他们的思维用逻辑一条条写下,放到计算机里就行……” 杨强在TEDxNanjing谈智能的起源
介绍:1)机器翻译Sequence to Sequence NIPS14 2)成分句法GRAMMAR AS FOREIGN LANGUAGE
介绍:网易有道的三位工程师写的word2vec的解析文档,从基本的词向量/统计语言模型->NNLM->Log-Linear /Log-Bilinear->层次化Log-Bilinear,到CBOW和Skip-gram模型,再到word2vec的各种tricks, 公式推导与代码,基本上是网上关于word2vec资料的大合集,对word2vec感兴趣的朋友可以看看
介绍:机器学习开源软件,收录了各种机器学习的各种编程语言学术与商业的开源软件.与此类似的还有很多例如:DMOZ – Computers: Artificial Intelligence: Machine Learning: Software, LIBSVM — A Library for Support Vector Machines, Weka 3: Data Mining Software in Java, scikit-learn:Machine Learning in Python, Natural Language Toolkit:NLTK, MAchine Learning for LanguagE Toolkit, Data Mining – Fruitful and Fun, Open Source Computer Vision Library
介绍:作者是计算机研二(写文章的时候,现在是2015年了应该快要毕业了),专业方向自然语言处理.这是一点他的经验之谈.对于入门的朋友或许会有帮助
介绍:这是一篇关于机器学习算法分类的文章,非常好
介绍:机器学习日报里面推荐很多内容,在这里有一部分的优秀内容就是来自机器学习日报.
介绍:这是一篇关于图像分类在深度学习中的文章
介绍:作者与Bengio的兄弟Samy 09年合编《自动语音识别:核方法》 3)李开复1989年《自动语音识别》专著,其博导、94年图灵奖得主Raj Reddy作序
介绍: 作者是360电商技术组成员,这是一篇NLP在中文分词中的应用
介绍: 使用deep learning的人脸关键点检测,此外还有一篇AWS部署教程
介绍: 由Sebastian Nowozin等人编纂MIT出版的新书《Advanced Structured Prediction》http://t.cn/RZxipKG ,汇集了结构化预测领域诸多牛文,涉及CV、NLP等领域,值得一读。网上公开的几章草稿:一,二,三,四,五
介绍: Tropp把数学家用高深装逼的数学语言写的矩阵概率不等式用初等的方法写出来,是非常好的手册,领域内的paper各种证明都在用里面的结果。虽说是初等的,但还是非常的难
介绍: 不容错过的免费大数据集,有些已经是耳熟能详,有些可能还是第一次听说,内容跨越文本、数据、多媒体等,让他们伴你开始数据科学之旅吧,具体包 括:Data.gov、US Census Bureau、European Union Open Data Portal、Data.gov.uk等
介绍: 谷歌科学家、Hinton亲传弟子Ilya Sutskever的深度学习综述及实际建议
介绍: 非常好的讨论递归神经网络的文章,覆盖了RNN的概念、原理、训练及优化等各个方面内容,强烈推荐!本文作者Nikhil Buduma还有一篇Deep Learning in a Nutshell值得推荐
介绍:里面融合了很多的资源,例如竞赛,在线课程,demo,数据整合等。有分类
介绍:《机器学习的统计基础》在线版,该手册希望在理论与实践之间找到平衡点,各主要内容都伴有实际例子及数据,书中的例子程序都是用R语言编写的。
介绍:IVAN VASILEV写的深度学习导引:从浅层感知机到深度网络。高可读
介绍:鲁棒及有益的人工智能优先研究计划:一封公开信,目前已经有Stuart Russell, Tom Dietterich, Eric Horvitz, Yann LeCun, Peter Norvig, Tom Mitchell, Geoffrey Hinton, Elon Musk等人签署The Future of Life Institute (FLI). 这封信的背景是最近霍金和Elon Musk提醒人们注意AI的潜在威胁。公开信的内容是AI科学家们站在造福社会的角度,展望人工智能的未来发展方向,提出开发AI系统的 Verification,Validity, Security, Control四点要求,以及需要注意的社会问题。毕竟当前AI在经济领域,法律,以及道德领域相关研究较少。其实还有一部美剧《疑犯追踪》,介绍了AI的演进从一开始的自我学习,过滤,图像识别,语音识别等判断危险,到第四季的时候出现了机器通过学习成长之后想控制世界的状态。说到这里推荐收看。
介绍:里面根据词条提供了许多资源,还有相关知识结构,路线图,用时长短等。号称是”机器学习“搜索引擎
介绍:Facebook人工智能研究院(FAIR)开源了一系列软件库,以帮助开发者建立更大、更快的深度学习模型。开放的软件库在 Facebook 被称作模块。用它们替代机器学习领域常用的开发环境 Torch 中的默认模块,可以在更短的时间内训练更大规模的神经网络模型。
介绍:本文虽然是写于2012年,但是这篇文章完全是作者的经验之作。
介绍:本文是对《机器学习实战》作者Peter Harrington做的一个访谈。包含了书中部分的疑问解答和一点个人学习建议
介绍:非常好的深度学习概述,对几种流行的深度学习模型都进行了介绍和讨论
介绍:主要是讲述了利用R语言进行数据挖掘
介绍:帮你理解卷积神经网络,讲解很清晰,此外还有两篇Conv Nets: A Modular Perspective,Groups & Group Convolutions. 作者的其他的关于神经网络文章也很棒
介绍:Deep Learning算法介绍,里面介绍了06年3篇让deep learning崛起的论文
介绍:一本学习人工智能的书籍,作者是Yoshua Bengio,相关国内报道
介绍:Geoffrey Hinton是Deep Learning的大牛,他的主页放了一些介绍性文章和课件值得学习
介绍:概率论:数理逻辑书籍
介绍:一个用来快速的统计,机器学习并且对于数据量大的数学库
介绍:在这里你可以看到最近深度学习有什么新动向。
介绍:此书在信息检索领域家喻户晓, 除提供该书的免费电子版外,还提供一个IR资源列表 ,收录了信息检索、网络信息检索、搜索引擎实现等方面相关的图书、研究中心、相关课程、子领域、会议、期刊等等,堪称全集,值得收藏
介绍:信息几何学及其在机器学习中的应用
介绍:课程《法律分析》介绍幻灯片。用机器学习解决法律相关分析和预测问题,相关的法律应用包括预测编码、早期案例评估、案件整体情况的预测,定价和工作人员预测,司法行为预测等。法律领域大家可能都比较陌生,不妨了解下。
介绍: 文中提到了最优,模型,最大熵等等理论,此外还有应用篇。推荐系统可以说是一本不错的阅读稿,关于模型还推荐一篇Generative Model 与 Discriminative Model
介绍: NeuralTalk is a Python+numpy project for learning Multimodal Recurrent Neural Networks that describe images with sentences.NeuralTalk是一个Python的从图像生成自然语言描述的工具。它实现了Google (Vinyals等,卷积神经网络CNN + 长短期记忆LSTM) 和斯坦福 (Karpathy and Fei-Fei, CNN + 递归神经网络RNN)的算法。NeuralTalk自带了一个训练好的动物模型,你可以拿狮子大象的照片来试试看
介绍:本文主要介绍了在Hadoop2.0上使用深度学习,文章来自paypal
介绍:用基于梯度下降的方法训练深度框架的实践推荐指导,作者是Yoshua Bengio .感谢@xuewei4d 推荐
介绍: 用统计和因果方法做机器学习(视频报告)
介绍: 一个讲机器学习的Youtube视频教程。160集。系统程度跟书可比拟。
介绍: 机器学习中的数学,作者的研究方向是机器学习,并行计算如果你还想了解一点其他的可以看看他博客的其他文章
介绍: 美团推荐算法实践,从框架,应用,策略,查询等分析
介绍: 深度学习用于问答系统答案句的选取
介绍: CNN用于WEB搜索,深度学习在文本计算中的应用
介绍: Awesome系列中的公开数据集
介绍: 一个学术搜索引擎
介绍: 用Python和Cython写的工业级自然语言处理库,号称是速度最快的NLP库,快的原因一是用Cython写的,二是用了个很巧妙的hash技术,加速系统的瓶颈,NLP中稀松特征的存取
介绍: Fields是个数学研究中心,上面的这份ppt是来自Fields举办的活动中Russ Salakhutdinov带来的《大规模机器学习》分享
介绍: Topic modeling 的经典论文,标注了关键点
介绍: 多伦多大学与Google合作的新论文,深度学习也可以用来下围棋,据说能达到六段水平
介绍: 新闻,paper,课程,book,system,CES,Roboot,此外还推荐一个深度学习入门与综述资料
介绍: 18 free eBooks on Machine Learning
介绍:Chief scientist of Noah’s Ark Lab of Huawei Technologies.He worked at the Research Laboratories of NEC Corporation during 1990 and 2001 and Microsoft Research Asia during 2001 and 2012.Paper
介绍: DEEPLEARNING.UNIVERSITY的论文库已经收录了963篇经过分类的深度学习论文了,很多经典论文都已经收录
介绍: Radim Řehůřek(Gensim开发者)在一次机器学习聚会上的报告,关于word2vec及其优化、应用和扩展,很实用.国内网盘
介绍:很多公司都用机器学习来解决问题,提高用户体验。那么怎么可以让机器学习更实时和有效呢?Spark MLlib 1.2里面的Streaming K-means,由斑马鱼脑神经研究的Jeremy Freeman脑神经科学家编写,最初是为了实时处理他们每半小时1TB的研究数据,现在发布给大家用了。
介绍: 这是一篇面向工程师的LDA入门笔记,并且提供一份开箱即用Java实现。本文只记录基本概念与原理,并不涉及公式推导。文中的LDA实现核心部分采用了arbylon的LdaGibbsSampler并力所能及地注解了,在搜狗分类语料库上测试良好,开源在GitHub上。
介绍: AMiner是一个学术搜索引擎,从学术网络中挖掘深度知识、面向科技大数据的挖掘。收集近4000万作者信息、8000万论文信息、1亿多引用关系、链接近8百万知识点;支持专家搜索、机构排名、科研成果评价、会议排名。
介绍: Quora上的主题,讨论Word2Vec的有趣应用,Omer Levy提到了他在CoNLL2014最佳论文里的分析结果和新方法,Daniel Hammack给出了找特异词的小应用并提供了(Python)代码
介绍: 机器学习公开课汇总,虽然里面的有些课程已经归档过了,但是还有个别的信息没有。感谢课程图谱的小编
介绍: 【A First Course in Linear Algebra】Robert Beezer 有答案 有移动版、打印版 使用GNU自由文档协议 引用了杰弗逊1813年的信
介绍:libfacedetection是深圳大学开源的一个人脸图像识别库。包含正面和多视角人脸检测两个算法.优点:速度快(OpenCV haar+adaboost的2-3倍), 准确度高 (FDDB非公开类评测排名第二),能估计人脸角度。
介绍:WSDM2015最佳论文 把马尔可夫链理论用在了图分析上面,比一般的propagation model更加深刻一些。通过全局的平稳分布去求解每个节点影响系数模型。假设合理(转移受到相邻的影响系数影响)。可以用来反求每个节点的影响系数
介绍:机器学习入门书籍,具体介绍
介绍: 非常棒的强调特征选择对分类器重要性的文章。情感分类中,根据互信息对复杂高维特征降维再使用朴素贝叶斯分类器,取得了比SVM更理想的效果,训练和分类时间也大大降低——更重要的是,不必花大量时间在学习和优化SVM上——特征也一样no free lunch
介绍:CMU的统计系和计算机系知名教授Larry Wasserman 在《机器崛起》,对比了统计和机器学习的差异
介绍:随着大数据时代的到来,机器学习成为解决问题的一种重要且关键的工具。不管是工业界还是学术界,机器学习都是一个炙手可热的方向,但是学术界 和工业界对机器学习的研究各有侧重,学术界侧重于对机器学习理论的研究,工业界侧重于如何用机器学习来解决实际问题。这篇文章是美团的实际环境中的实战篇
介绍:面向机器学习的高斯过程,章节概要:回归、分类、协方差函数、模型选择与超参优化、高斯模型与其他模型关系、大数据集的逼近方法等,微盘下载
介绍:Python下的文本模糊匹配库,老库新推,可计算串间ratio(简单相似系数)、partial_ratio(局部相似系数)、token_sort_ratio(词排序相似系数)、token_set_ratio(词集合相似系数)等 github
介绍:Blocks是基于Theano的神经网络搭建框架,集成相关函数、管道和算法,帮你更快地创建和管理NN模块.
介绍:机器学习大神Alex Smola在CMU新一期的机器学习入门课程”Introduction to Machine Learning“近期刚刚开课,课程4K高清视频同步到Youtube上,目前刚刚更新到 2.4 Exponential Families,课程视频playlist, 感兴趣的同学可以关注,非常适合入门.
介绍:用社交用户行为学习图片的协同特征,可更好地表达图片内容相似性。由于不依赖于人工标签(标注),可用于大规模图片处理,难在用户行为数据的获取和清洗;利用社会化特征的思路值得借鉴.
介绍:Twitter技术团队对前段时间开源的时间序列异常检测算法(S-H-ESD)R包的介绍,其中对异常的定义和分析很值得参考,文中也提到——异常是强针对性的,某个领域开发的异常检测在其他领域直接用可不行.
介绍:聚焦数据质量问题的应对,数据质量对各种规模企业的性能和效率都至关重要,文中总结出(不限于)22种典型数据质量问题显现的信号,以及典型的数据质量解决方案(清洗、去重、统一、匹配、权限清理等)
介绍:中文分词入门之资源.
介绍:15年旧金山深度学习峰会视频集萃,国内云盘
介绍:很好的条件随机场(CRF)介绍文章,作者的学习笔记
介绍: 来自Stanford,用神经网络实现快速准确的依存关系解析器
介绍:做深度学习如何选择GPU的建议
介绍: Stanford的Trevor Hastie教授在H2O.ai Meet-Up上的报告,讲稀疏线性模型——面向“宽数据”(特征维数超过样本数)的线性模型,13年同主题报告 、讲义.
介绍: 分类整理的机器视觉相关资源列表,秉承Awesome系列风格,有质有量!作者的更新频率也很频繁
介绍: social networks course
介绍: 大规模机器学习流程的构建与部署.
介绍: 人脸识别二次开发包,免费,可商用,有演示、范例、说明书.
介绍: 采用Torch用深度学习网络理解NLP,来自Facebook 人工智能的文章.
介绍: 来自CMU的Ed Hovy和Stanford的Jiwei Li一篇有意思的Arxiv文章,作者用Shannon Entropy来刻画NLP中各项任务的难度.
介绍: 信息检索排序模型BM25(Besting Matching)。1)从经典概率模型演变而来 2)捕捉了向量空间模型中三个影响索引项权重的因子:IDF逆文档频率;TF索引项频率;文档长度归一化。3)并且含有集成学习的思想:组合了BM11和 BM15两个模型。4)作者是BM25的提出者和Okapi实现者Robertson.
介绍: 自回归滑动平均(ARMA)时间序列的简单介绍,ARMA是研究时间序列的重要方法,由自回归模型(AR模型)与滑动平均模型(MA模型)为基础“混合”构成.
介绍: 把来自target的attention signal加入source encoding CNN的输入,得到了比BBN的模型好的多neural network joint model
介绍: 揭开印度菜的美味秘诀——通过对大量食谱原料关系的挖掘,发现印度菜美味的原因之一是其中的味道互相冲突,很有趣的文本挖掘研究
介绍: HMM相关文章,此外推荐中文分词之HMM模型详解
介绍: 1)词频与其降序排序的关系,最著名的是语言学家齐夫(Zipf,1902-1950)1949年提出的Zipf‘s law,即二者成反比关系. 曼德勃罗(Mandelbrot,1924- 2010)引入参数修正了对甚高频和甚低频词的刻画 2)Heaps’ law: 词汇表与语料规模的平方根(这是一个参数,英语0.4-0.6)成正比
介绍: Jürgen Schmidhuber在Reddit上的AMA(Ask Me Anything)主题,有不少RNN和AI、ML的干货内容,关于开源&思想&方法&建议……耐心阅读,相信你也会受益匪浅.
介绍: 成G上T的学术数据,HN近期热议话题,主题涉及机器学习、NLP、SNA等。下载最简单的方法,通过BT软件,RSS订阅各集合即可
介绍: Scikit-Learn官网提供,在原有的Cheat Sheet基础上加上了Scikit-Learn相关文档的链接,方便浏览
介绍: 深度学习的全面硬件指南,从GPU到RAM、CPU、SSD、PCIe
介绍:Pedestrian Detection paper & data
介绍: 【神经科学碰撞人工智能】在脸部识别上你我都是专家,即使细微的差别也能辨认。研究已证明人类和灵长类动物在面部加工上不同于其他物种,人类使用梭状回面 孔区(FFA)。Khaligh-Razavi等通过计算机模拟出人脸识别的FFA活动,堪称神经科学与人工智能的完美结合。
介绍: 神经网络C++教程,本文介绍了用可调节梯度下降和可调节动量法设计和编码经典BP神经网络,网络经过训练可以做出惊人和美妙的东西出来。此外作者博客的其他文章也很不错。
介绍:deeplearning4j官网提供的实际应用场景NN选择参考表,列举了一些典型问题建议使用的神经网络
介绍:一个深度学习项目,提供了Python, C/C++, Java, Scala, Go多个版本的代码
介绍:深度学习教程,github
介绍:自然语言处理的发展趋势——访卡内基梅隆大学爱德华·霍威教授.
介绍:Google对Facebook DeepFace的有力回击—— FaceNet,在LFW(Labeled Faces in the Wild)上达到99.63%准确率(新纪录),FaceNet embeddings可用于人脸识别、鉴别和聚类.
介绍:本文来自Databricks公司网站的一篇博客文章,由Joseph Bradley和Manish Amde撰写,文章主要介绍了Random Forests和Gradient-Boosted Trees(GBTs)算法和他们在MLlib中的分布式实现,以及展示一些简单的例子并建议该从何处上手.中文版.
介绍:华盛顿大学Pedro Domingos团队的DNN,提供论文和实现代码.
介绍:基于神经网络的自然语言依存关系解析器(已集成至Stanford CoreNLP),特点是超快、准确,目前可处理中英文语料,基于《A Fast and Accurate Dependency Parser Using Neural Networks》 思路实现.
介绍:本文根据神经网络的发展历程,详细讲解神经网络语言模型在各个阶段的形式,其中的模型包含NNLM[Bengio,2003]、 Hierarchical NNLM[Bengio, 2005], Log-Bilinear[Hinton, 2007],SENNA等重要变形,总结的特别好.
介绍:经典问题的新研究:利用文本和可读性特征分类垃圾邮件。
介绍:Kaggle脑控计算机交互(BCI)竞赛优胜方案源码及文档,包括完整的数据处理流程,是学习Python数据处理和Kaggle经典参赛框架的绝佳实例
介绍:IPOL(在线图像处理)是图像处理和图像分析的研究期刊,每篇文章都包含一个算法及相应的代码、Demo和实验文档。文本和源码是经过了同行评审的。IPOL是开放的科学和可重复的研究期刊。我一直想做点类似的工作,拉近产品和技术之间的距离.
介绍:出自MIT,研究加密数据高效分类问题.
介绍:新加坡LV实验室的神经网络并行框架Purine: A bi-graph based deep learning framework,支持构建各种并行的架构,在多机多卡,同步更新参数的情况下基本达到线性加速。12块Titan 20小时可以完成Googlenet的训练。
介绍:这是一个机器学习资源库,虽然比较少.但蚊子再小也是肉.有突出部分.此外还有一个由zheng Rui整理的机器学习资源.
介绍:Chase Davis在NICAR15上的主题报告材料,用Scikit-Learn做监督学习的入门例子.
介绍:这是一本自然语言处理的词典,从1998年开始到目前积累了成千上万的专业词语解释,如果你是一位刚入门的朋友.可以借这本词典让自己成长更快.
介绍:通过分析1930年至今的比赛数据,用PageRank计算世界杯参赛球队排行榜.
介绍:R语言教程,此外还推荐一个R语言教程An Introduction to R.
介绍:经典老文,复杂网络社区发现的高效算法,Gephi中的Community detection即基于此.
介绍: 一个面向 .net 的开源机器学习库,github地址
介绍: 支持node.js的JS神经网络库,可在客户端浏览器中运行,支持LSTM等 github地址
介绍: 决策树
介绍: 讨论深度学习自动编码器如何有效应对维数灾难,国内翻译
介绍: CMU的优化与随机方法课程,由A. Smola和S. Sra主讲,优化理论是机器学习的基石,值得深入学习 国内云(视频)
介绍: “面向视觉识别的CNN”课程设计报告集锦.近百篇,内容涉及图像识别应用的各个方面
介绍:用Spark的MLlib+GraphX做大规模LDA主题抽取.
介绍: 基于深度学习的多标签分类,用基于RBM的DBN解决多标签分类(特征)问题
介绍: DeepMind论文集锦
介绍: 一个开源语音识别工具包,它目前托管在sourceforge上面
介绍: 免费电子书《数据新闻手册》, 国内有热心的朋友翻译了中文版,大家也可以在线阅读
介绍: 零售领域的数据挖掘文章.
介绍: 深度学习卷积概念详解,深入浅出.
介绍: 非常强大的Python的数据分析工具包.
介绍: 2015文本分析(商业)应用综述.
介绍: 深度学习框架、库调研及Theano的初步测试体会报告.
介绍: MIT的Yoshua Bengio, Ian Goodfellow, Aaron Courville著等人讲深度学习的新书,还未定稿,线上提供Draft chapters收集反馈,超赞!强烈推荐.
介绍: Python下开源可持久化朴素贝叶斯分类库.
介绍:Paracel is a distributed computational framework designed for machine learning problems, graph algorithms and scientific computing in C++.
介绍: 开源汉语言处理包.
介绍: 使用Ruby实现简单的神经网络例子.
介绍:神经网络黑客入门.
介绍:好多数据科学家名人推荐,还有资料.
介绍:实现项目已经开源在github上面Crepe
介绍:作者发现,经过调参,传统的方法也能和word2vec取得差不多的效果。另外,无论作者怎么试,GloVe都比不过word2vec.
介绍:Stanford深度学习与自然语言处理课程,Richard Socher主讲.
介绍:机器学习中的重要数学概念.
介绍:用于改进语义表示的树型LSTM递归神经网络,句子级相关性判断和情感分类效果很好.实现代码.
介绍:卡耐基梅隆Ryan Tibshirani和Larry Wasserman开设的机器学习课程,先修课程为机器学习(10-715)和中级统计学(36-705),聚焦统计理论和方法在机器学习领域应用.
介绍:《哈佛大学蒙特卡洛方法与随机优化课程》是哈佛应用数学研究生课程,由V Kaynig-Fittkau、P Protopapas主讲,Python程序示例,对贝叶斯推理感兴趣的朋友一定要看看,提供授课视频及课上IPN讲义.
介绍:生物医学的SPARK大数据应用.并且伯克利开源了他们的big data genomics系统ADAM,其他的内容可以关注一下官方主页.
介绍:对自然语言处理技术或者机器翻译技术感兴趣的亲们,请在提出自己牛逼到无以伦比的idea(自动归纳翻译规律、自动理解语境、自动识别语义等等)之前,请通过谷歌学术简单搜一下,如果谷歌不可用,这个网址有这个领域几大顶会的论文列表,切不可断章取义,胡乱假设.
介绍:论文+代码:基于集成方法的Twitter情感分类,实现代码.
介绍:NIPS CiML 2014的PPT,NIPS是神经信息处理系统进展大会的英文简称.
介绍:斯坦福的深度学习课程的Projects 每个人都要写一个论文级别的报告 里面有一些很有意思的应用 大家可以看看 .
介绍:R语言线性回归多方案速度比较具体方案包括lm()、nls()、glm()、bayesglm()、nls()、mle2()、optim()和Stan’s optimizing()等.
介绍:文中提到的三篇论文(机器学习那些事、无监督聚类综述、监督分类综述)都很经典,Domnigos的机器学习课也很精彩
介绍:莱斯大学(Rice University)的深度学习的概率理论.
介绍:基于马尔可夫链自动生成啤酒评论的开源Twitter机器人,github地址.
介绍:视频+讲义:深度学习用于自然语言处理教程(NAACL13).
介绍:用机器学习做数据分析,David Taylor最近在McGill University研讨会上的报告,还提供了一系列讲机器学习方法的ipn,很有价值 GitHub.国内
介绍:基于CNN+LSTM的视频分类,google演示.
介绍:Quora怎么用机器学习.
介绍:亚马逊在机器学习上面的一些应用,代码示例.
介绍:并行机器学习指南(基于scikit-learn和IPython).notebook
介绍:DataSchool的机器学习基本概念教学.
介绍:一个基于OpenGL实现的卷积神经网络,支持Linux及Windows系.
介绍:基于Mahout和Elasticsearch的推荐系统.
介绍:Francis X. Diebold的《(经济|商业|金融等领域)预测方法.
介绍:Francis X. Diebold的《时序计量经济学》.
介绍:基于Yelp数据集的开源情感分析工具比较,评测覆盖Naive Bayes、SentiWordNet、CoreNLP等 .
介绍:国内Pattern Recognition And Machine Learning读书会资源汇总,各章pdf讲稿,博客.
介绍:用于Web分析和数据挖掘的概率数据结构.
介绍:机器学习在导航上面的应用.
介绍:Neural Networks Demystified系列视频,Stephen Welch制作,纯手绘风格,浅显易懂,国内云.
介绍:{swirl}数据训练营:R&数据科学在线交互教程.
介绍:关于深度学习和RNN的讨论 Sequence to Sequence Learning with Neural Networks.
介绍:Deep Reinforcement Learning.
介绍:(PyCon2015)Scikit-Learn机器学习教程,Parallel Machine Learning with scikit-learn and IPython.
介绍:PDNN: A Python Toolkit for Deep Learning.
介绍:15年春季学期CMU的机器学习课程,由Alex Smola主讲,提供讲义及授课视频,很不错.国内镜像.
介绍:大数据处理课.内容覆盖流处理、MapReduce、图算法等.
介绍:用Spark MLlib实现易用可扩展的机器学习,国内镜像.
介绍:以往上千行代码概率编程(语言)实现只需50行.
介绍:ggplot2速查小册子,另外一个,此外还推荐《A new data processing workflow for R: dplyr, magrittr, tidyr, ggplot2》.
介绍:用结构化模型来预测实时股票行情.
介绍:国际人工智能联合会议录取论文列表,大部分论文可使用Google找到.
介绍:一般矩阵乘法(GEMM)对深度学习的重要性.
介绍:A Community of awesome Distributed Machine Learning C++ projects.
介绍:免费电子书<强化学习介绍>,第一版(1998),第二版(2015草稿),相关课程资料,Reinforcement Learning.
介绍:免费书:Azure ML使用精要.
介绍:A Deep Learning Tutorial: From Perceptrons to Deep Networks.
介绍:有趣的机器学习:最简明入门指南,中文版.
介绍:深度学习简明介绍,中文版.
介绍:Portable, scalable and reliable distributed machine learning.
介绍:CNN开源实现横向评测,参评框架包括Caffe 、Torch-7、CuDNN 、cudaconvnet2 、fbfft、Nervana Systems等,NervanaSys表现突出.
介绍:卡耐基梅隆大学计算机学院语言技术系的资源大全,包括大量的NLP开源软件工具包,基础数据集,论文集,数据挖掘教程,机器学习资源.
介绍:Twitter情感分析工具SentiTweet,视频+讲义.
介绍:华盛顿大学的Machine Learning Paper Repository.
介绍:机器学习速查表.
介绍:最新的Spark summit会议资料.
介绍:最新的Spark summit会议资料.
介绍:Ebook Learning Spark.
介绍:Ebook Advanced Analytics with Spark, Early Release Edition.
介绍:清华大学副教授,是图挖掘方面的专家。他主持设计和实现的Arnetminer是国内领先的图挖掘系统,该系统也是多个会议的支持商.
介绍:迁移学习的国际领军人物.
介绍:在半监督学习,multi-label学习和集成学习方面在国际上有一定的影响力.
介绍:信息检索,自然语言处理,机器翻译方面的专家.
介绍:吴军博士是当前Google中日韩文搜索算法的主要设计者。在Google其间,他领导了许多研发项目,包括许多与中文相关的产品和自然语言处理的项目,他的新个人主页.
介绍:喵星人相关论文集.
介绍:如何评价机器学习模型系列文章,How to Evaluate Machine Learning Models, Part 2a: Classification Metrics,How to Evaluate Machine Learning Models, Part 2b: Ranking and Regression Metrics.
介绍:Twitter新trends的基本实现框架.
介绍:Storm手册,国内有中文翻译版本,谢谢作者.
介绍:Java机器学习算法库SmileMiner.
介绍:机器翻译学术论文写作方法和技巧,Simon Peyton Jones的How to write a good research paper同类视频How to Write a Great Research Paper,how to paper talk.
介绍:神经网络训练中的Tricks之高效BP,博主的其他博客也挺精彩的.
介绍:作者是NLP方向的硕士,短短几年内研究成果颇丰,推荐新入门的朋友阅读.
介绍:UCLA的Jens Palsberg根据Google Scholar建立了一个计算机领域的H-index牛人列表,我们熟悉的各个领域的大牛绝大多数都在榜上,包括1位诺贝尔奖得主,35位图灵奖得主,近 百位美国工程院/科学院院士,300多位ACM Fellow,在这里推荐的原因是大家可以在google通过搜索牛人的名字来获取更多的资源,这份资料很宝贵.
介绍:用大型语料库学习概念的层次关系,如鸟是鹦鹉的上级,鹦鹉是虎皮鹦鹉的上级。创新性在于模型构造,用因子图刻画概念之间依存关系,因引入兄弟 关系,图有环,所以用有环扩散(loopy propagation)迭代计算边际概率(marginal probability).
介绍: 这是一款贝叶斯分析的商业软件,官方写的贝叶斯分析的手册有250多页,虽然R语言 已经有类似的项目,但毕竟可以增加一个可选项.
介绍:deep net highlights from 2014.
介绍:This paper proposes Fast R-CNN, a clean and fast framework for object detection.
介绍:提供计算机视觉、机器视觉应用的公司信息汇总.应用领域包括:自动辅助驾驶和交通管理、眼球和头部跟踪、影视运动分析、影视业、手势识别、通 用视觉系统、各种工业自动化和检验、医药和生物、移动设备目标识别和AR、人群跟踪、摄像、安全监控、生物监控、三维建模、web和云应用.
介绍:Python版可视化数据统计开源库.
介绍:麻省理工Gilbert Strang线性代数课程笔记,Gilbert Strang《Linear Algebra》课程主页视频+讲义.
介绍:面向机器学习/深度学习的数据向量化工具Canova,github, 支持CSV文件、MNIST数据、TF-IDF/Bag of Words/word2vec文本向量化.
介绍:快速入门:基于Apache Mahout的分布式机器学习.
介绍:基于scikit-learn讲解了一些机器学习技术,如SVM,NB,PCA,DT,以及特征工程、特征选择和模型选择问题.
介绍:基于Spark的高效机器学习,视频地址.
介绍:WePay用机器学习对抗信用卡”shell selling”诈骗.
介绍:16位数据科学家语录精选.
介绍:深度学习在大数据分析领域的应用和挑战.
介绍:免费的机器学习与数学书籍,除此之外还有其他的免费编程书籍,编程语言,设计,操作系统等.
介绍:一篇关于CNN模型对象识别Paper.
介绍:深度学习的统计分析V:泛化和正则化.
介绍:用SGD能高效完成训练的大规模(多层)深度网络HN.
介绍:深度学习解读文章.
介绍:Coursera上的推荐系统导论(Introduction to Recommender Systems)公开课.
介绍:Andrew Ng经典机器学习课程笔记.
介绍:ICLR 2015见闻录,博客的其他机器学习文章也不错.
介绍:推荐系统”个性化语义排序”模型.
介绍:激情时分更惜字——MIT的最新Twitter研究结果.
介绍:苏州大学人类语言技术研究相关论文.
介绍:实现神经图灵机(NTM),项目地址,此外推荐相关神经图灵机算法.
介绍:华盛顿大学的机器视觉(2015),参考资料Computer Vision: Algorithms and Applications.
介绍:”Mining of Massive Datasets”发布第二版,Jure Leskovec, Anand Rajaraman, Jeff Ullman 新版增加Jure Leskovec作为合作作者,新增社交网络图数据挖掘、降维和大规模机器学习三章,电子版依旧免费.
介绍:一个深度学习资源页,资料很丰富.
介绍:免费电子书”Learning Deep Learning”.
介绍:Machine Learning for Astronomy with scikit-learn.
介绍:免费电子书”随机森林入门指南”.
介绍:白话数据挖掘十大算法.
介绍:基于Mahout和Elasticsearch的推荐系统,国内译版.
介绍:博士学位论文:ELM研究进展.
介绍:Pandas十分钟速览,ipn.
介绍:面向数据新闻的文本挖掘.
介绍:用网络图片合成延时视频(SIGGRAPH 2015).
介绍:分类系统的维数灾难.
介绍:深度学习vs.大数据——从数据到知识:版权的思考,[翻译版](http://www.csdn.net/article/2015-05-19/2824707
介绍:预测模型入门.
介绍:深入浅出LSTM.
介绍:Ben Jones的数据可视化建议.
介绍:解读数据降维/PCA/SVD.
介绍:IPN:监督学习方法示例/对比参考表,覆盖logistic回归, 决策树, SVM, KNN, Naive Bayes等方法.
介绍:基于RankSVM和DNN自动(重组)生成Rap歌词.
介绍:随机索引RI词空间模型专题.
介绍:基于机器学习的漏洞检测工具VDiscover.
介绍:深度学习系统minerva。拥有python编程接口。多GPU几乎达到线性加速。在4块GPU上能在4天内将GoogLeNet训练到 68.7%的top-1以及89.0%的top-5准确率。和同为dmlc项目的cxxnet相比,采用动态数据流引擎,提供更多灵活性。未来将和 cxxnet一起整合为mxnet项目,互取优势.
介绍:2015年国际计算机视觉与模式识别会议paper.
介绍:Netflix工程总监眼中的分类算法:深度学习优先级最低,中文版.
介绍:Codalab图像标注竞赛排行+各家论文,Reddit上flukeskywalker整理了各家技术相关论文.
介绍:基于Caffe的加速深度学习系统CcT.
介绍:深度学习(模型)低精度(训练与)存储.
介绍:新书预览:模型机器学习.
介绍:免费电子书多臂老虎机,此外推荐Introduction to Bandits: Algorithms and Theory.
介绍:基于Kaggle’s Titanic Competition的交互式R机器学习教程,介绍《Interactive R Tutorial: Machine Learning for the Titanic Competition》.
介绍:Deep Learning(深度学习)学习笔记整理系列.
介绍:神经(感知)机器翻译介绍.
介绍:Andrew Ng关于深度学习/自学习/无监督特征学习的报告,国内云.
介绍:论文:通过潜在知识迁移训练RNN.
介绍:面向金融数据的情感分析工具.
介绍:(Python)主题模型交互可视化库pyLDAvis.
介绍:Logistic回归与优化实例教程.
介绍:贾扬清(谷歌大脑科学家、caffe缔造者)微信讲座记录.
介绍:Theano/Blocks实现RNN手写字符串生成sketch.
介绍:基于TopSig的海量(7亿+)网页聚类.
介绍:NAACL 2015 论文papers.
介绍:机器学习预测股市的七个问题.
介绍:神经网络学习资料推荐.
介绍:面向序列学习的RNN综述.
介绍:R文本处理手册.
介绍:“必看”的Python视频集锦.
介绍:Google(基础结构)栈.
介绍:矩阵和数据的随机算法(UC Berkeley 2013).
介绍:DataCamp中级R语言教程.
介绍:免费电子书:轻松掌握拓扑学,中文版.
介绍:Scikit-learn 是基于Scipy为机器学习建造的的一个Python模块,他的特色就是多样化的分类,回归和聚类的算法包括支持向量机,逻辑回归,朴素贝叶斯分类器,随 机森林,Gradient Boosting,聚类算法和DBSCAN。而且也设计出了Python numerical和scientific libraries Numpy and Scipy
介绍:Pylearn是一个让机器学习研究简单化的基于Theano的库程序。
介绍:NuPIC是一个以HTM学习算法为工具的机器智能平台。HTM是皮层的精确计算方法。HTM的核心是基于时间的持续学习算法和储存和撤销的时空模式。NuPIC适合于各种各样的问题,尤其是检测异常和预测的流数据来源。
介绍:Nilearn 是一个能够快速统计学习神经影像数据的Python模块。它利用Python语言中的scikit-learn 工具箱和一些进行预测建模,分类,解码,连通性分析的应用程序来进行多元的统计。
介绍:Pybrain是基于Python语言强化学习,人工智能,神经网络库的简称。 它的目标是提供灵活、容易使用并且强大的机器学习算法和进行各种各样的预定义的环境中测试来比较你的算法。
介绍:Pattern 是Python语言下的一个网络挖掘模块。它为数据挖掘,自然语言处理,网络分析和机器学习提供工具。它支持向量空间模型、聚类、支持向量机和感知机并且用KNN分类法进行分类。
介绍:Fuel为你的机器学习模型提供数据。他有一个共享如MNIST, CIFAR-10 (图片数据集), Google’s One Billion Words (文字)这类数据集的接口。你使用他来通过很多种的方式来替代自己的数据。
介绍:Bob是一个免费的信号处理和机器学习的工具。它的工具箱是用Python和C++语言共同编写的,它的设计目的是变得更加高效并且减少开发时间,它是由处理图像工具,音频和视频处理、机器学习和模式识别的大量软件包构成的。
介绍:Skdata是机器学习和统计的数据集的库程序。这个模块对于玩具问题,流行的计算机视觉和自然语言的数据集提供标准的Python语言的使用。
介绍:MILK是Python语言下的机器学习工具包。它主要是在很多可得到的分类比如SVMS,K-NN,随机森林,决策树中使用监督分类法。 它还执行特征选择。 这些分类器在许多方面相结合,可以形成不同的例如无监督学习、密切关系金传播和由MILK支持的K-means聚类等分类系统。
介绍:IEPY是一个专注于关系抽取的开源性信息抽取工具。它主要针对的是需要对大型数据集进行信息提取的用户和想要尝试新的算法的科学家。
介绍:Quepy是通过改变自然语言问题从而在数据库查询语言中进行查询的一个Python框架。他可以简单的被定义为在自然语言和数据库查询中不 同类型的问题。所以,你不用编码就可以建立你自己的一个用自然语言进入你的数据库的系统。现在Quepy提供对于Sparql和MQL查询语言的支持。并 且计划将它延伸到其他的数据库查询语言。
介绍:Hebel是在Python语言中对于神经网络的深度学习的一个库程序,它使用的是通过PyCUDA来进行GPU和CUDA的加速。它是最重要的神经网络模型的类型的工具而且能提供一些不同的活动函数的激活功能,例如动力,涅斯捷罗夫动力,信号丢失和停止法。
介绍:它是一个由有用的工具和日常数据科学任务的扩展组成的一个库程序。
介绍:这个程序包容纳了大量能对你完成机器学习任务有帮助的实用程序模块。其中大量的模块和scikit-learn一起工作,其它的通常更有用。
介绍:Ramp是一个在Python语言下制定机器学习中加快原型设计的解决方案的库程序。他是一个轻型的pandas-based机器学习中可插 入的框架,它现存的Python语言下的机器学习和统计工具(比如scikit-learn,rpy2等)Ramp提供了一个简单的声明性语法探索功能从 而能够快速有效地实施算法和转换。
介绍:这一系列工具通过与scikit-learn兼容的API,来创建和测试机器学习功能。这个库程序提供了一组工具,它会让你在许多机器学习程 序使用中很受用。当你使用scikit-learn这个工具时,你会感觉到受到了很大的帮助。(虽然这只能在你有不同的算法时起作用。)
介绍:REP是以一种和谐、可再生的方式为指挥数据移动驱动所提供的一种环境。它有一个统一的分类器包装来提供各种各样的操作,例如TMVA, Sklearn, XGBoost, uBoost等等。并且它可以在一个群体以平行的方式训练分类器。同时它也提供了一个交互式的情节。
介绍:用亚马逊的机器学习建造的简单软件收集。
介绍:这是一个在Python语言下基于scikit-learn的极端学习机器的实现。
介绍:电子书降维方法,此外还推荐Dimensionality Reduction A Short Tutorial、Matlab Toolbox for Dimensionality Reduction、Unsupervised Kernel Dimension Reduction
介绍:deeplearning.net整理的深度学习数据集列表.
介绍:Go语言编写的自然语言处理工具.
介绍:词频模型对词向量的反击,参考Improving Distributional Similarity with Lessons Learned from Word Embeddings 。
介绍:预测模型的三个方面.
介绍:斯坦福大学深度学习与自然语言处理课程,部分课程笔记词向量、引言
介绍:CVPR2015上Google的CV研究列表.
介绍:利用(Metamind)深度学习自动发现篮球赛精彩片段.
介绍:对本土化特征学习的分析
Free Resources for Beginners on Deep Learning and Neural Network
By
Source: http://www.analyticsvidhya.com/blog/2015/11/free-resources-beginners-deep-learning-neural-network/
Introduction
Machines have already started their march towards artificial intelligence. Deep Learning and Neural Networks are probably the hottest topics in machine learning research today. Companies like Google, Facebook and Baidu are heavily investing into this field of research.
Researchers believe that machine learning will highly influence human life in near future. Human tasks will be automated using robots with negligible margin of error. I’m sure many of us would never have imagined such gigantic power of machine learning.
To ignite your desire, I’ve listed the best tutorials on Deep Learning and Neural Networks available on internet today. I’m sure this would be of your help! Take your first step today.
Time for some motivation here. You ‘must’ watch this before scrolling further. This ~3min video was released yesterday by Google. Enjoy!
Time for proceed further. Firstly, let’s understand Deep Learning and Neural Network in simple terms.
What is Neural Network?
The concept of Neural Network began way back in 1980s. But, has gained re-ignited interest in recent times. Neural network is originally a biological phenomenon. Neural network is a ‘network’ of interconnected neurons which maintain a high level of coordination to receive and transmit messages to brain & spinal cord. In machine learning, we refer Neural Network as ‘Artificial Neural Network’.
Artificial Neural Network, as the name suggests, is a network (layer) of artificially created ‘neurons’ which are then taught to adapt cognitive skills to function like human brain. Image Recognition, Voice Recognition, Soft Sensors, Anomaly detection, Time Series Predictions etc are all applications of ANN.
What is Deep Learning?
In simple words, Deep Learning can be understood as an algorithm which is composed of hidden layers of multiple neural networks. It works on unsupervised data and is known to provide accurate results than traditional ML algorithms.
Input data is passed through this algorithm, which is then passed through several non-linearities before delivering output. This algorithm allows us to go ‘deeper’ (higher level of abstraction) in the network without ending up writing lot of duplicated code, unlike ‘shallow’ algorithms. As it goes deeper and deeper, it filter the complex features and combines with those of previous layer, thus better results.
Algorithms like Decision Trees, SVM, Naive Bayes are ‘shallow’ algorithm. These involves writing lot of duplicated code and cause trouble reusing previous computations.
Deep Learning through Neural Network and takes us a step closer to Artificial Intelligence.
What do Experts have to say?
Early this years, AMAs took place on Reddit with the masters of Deep Learning and Neural Network. Considering my ever rising craze to dig latest information about this field, I got the chance to attend their AMA session. Let’s see what they have to said about the existence and future of this field:

Geoffrey Hinton said, ‘The brain has about 1014 synapses and we only live for about 109 seconds. So we have a lot more parameters than data. This motivates the idea that we must do a lot of unsupervised learning since the perceptual input (including proprioception) is the only place we can get 105 dimensions of constraint per second.’

Yann LeCunn, on emotions in robot, said, ‘Emotions do not necessarily lead to irrational behavior. They sometimes do, but they also often save our lives. If emotions are anticipations of outcome (like fear is the anticipation of impending disasters or elation is the anticipation of pleasure), or if emotions are drives to satisfy basic ground rules for survival (like hunger, desire to reproduce), then intelligent agent will have to have emotions’

Yoshua Bengio said, ‘Recurrent or recursive nets are really useful tools for modelling all kinds of dependency structures on variable-sized objects. We have made progress on ways to train them and it is one of the important areas of current research in the deep learning community. Examples of applications: speech recognition (especially the language part), machine translation, sentiment analysis, speech synthesis, handwriting synthesis and recognition, etc.’

Jurgen Schmidhuber says, ’20 years from now we’ll have 10,000 times faster computers for the same price, plus lots of additional medical data to train them. I assume that even the already existing neural network algorithms will greatly outperform human experts in most if not all domains of medical diagnosis, from melanoma detection to plaque detection in arteries, and innumerable other applications.’
P.S. I am by no means an expert on Neural Networks. In fact, I have just started my journey in this fascinating world. If you think, there are other free good resources which I have not shared below, please feel free to provide the suggestions
Below is the list of free resources useful to master these useful concepts:
Courses
Machine Learning by Andrew Ng: If you are a complete beginner to machine learning and neural networks, this course is the best place to start. Enrollments for the current batch ends on Nov 7, 2015. This course provides a broad introduction to machine learning, deep learning, data mining, neural networks using some useful case studies. You’ll also learn about the best practices of these algorithms and where are we heading with them
Neural Network Course on Coursera: Who could teach Neural Network better than Hinton himself? This is a highly recommended course on Neural Network. Though, it is archived now, you can still access the course material. It’s a 8 week long course and would require you to dedicate atleast 7-9 hours/week. This course expects prior knowledge of Python / Octave / Matlab and good hold on mathematical concepts (vector, calculus, algebra).
In addition to the course above, I found useful slides and lecture notes of Deep Learning programs from a few top universities of the world:
Carnegie Mellon University – Deep Learning : This course ended on 21st October 2015. It is archived now. But, you can still access the slides shared during this course. Learning from slide is an amazing way to understand concepts quickly. These slides cover all the aspects of deep learning to a certain point. I wouldn’t recommend this study material for beginners but to intermediates and above in this domain.
Deep Learning for NLP – This conference happened in 2013 on Human Language Technologies. The best part was, the knowledge which got shared. The slides and videos and well accessible and comprises of simple explanation of complex concepts. Beginners will find it worth watching these videos as the instructor begins the session from Logistic Regression and dives deeper into the use of machine learning algorithms.
Deep Learning for Computer Vision – This course was commenced at the starting of year 2015 by Columbia University. It focuses on deep learning techniques for vision and natural language processing problems. This course embraces theano as the programming tool. This course requires prior knowledge in Python and NumPy programming, NLP and Machine Learning.
Deep Learning: This is an archived course. It happened in Spring 2014. It was instructed by Yann LeCunn. This is a graduate course on Deep Learning. The precious slides and videos are accessible. I’d highly recommend this course to beginners. You’d amazed by the way LeCunn explains. Very simple and apt. To get best out of this course, I’d suggest you to work on assignments too, for your self evaluation.
Books

This book is written by Christopher M Bishop. This book serves as a excellent reference for students keen to understand the use of statistical techniques in machine learning and pattern recognition. This books assumes the knowledge of linear algebra and multivariate calculus. It provides a comprehensive introduction to statistical pattern recognition techniques using practice exercises.
Because of the rapid development and active research in the field, there aren’t many printed and accessible books available on Deep Learning. However, I found that Yoshua Bengio, along with Ian Goodfellow and Aaron Courville is working on a book. You can check its recent developments here.
Neural Networks and Deep Learning: This book is written by Michael Neilson. It is available FREE online. If you are good at learning things at your own pace, I’d suggest you to read this book. There are just 6 Chapters. Every chapters goes in great detail of concepts related to deep learning using really nice illustrations.
Blogs
Here are some of the best bet I have come across:
Beginners
Introduction to Neural Networks : This is Chapter 10 of Book, ‘The Nature of Code’. You’ll find the reading style simple and easy to comprehend. The author has explained neural network from scratch. Along with theory, you’ll also find codes(in python) to practice and apply them at your them. This not only would give you confidence to learn these concept, but would also allow you to experience their impact.
Hacker’s Guide to Neural Networks : Though, the codes in this blog are written in Javascript which you might not know. I’d still suggest you to refer it for the simplicity of theoretical concepts. This tutorial has very little math, but you’ll need lots of logic to comprehend and understand the following parts.
Intermediates
Recurrent Neural Network Part 1, Part 2, Part 3, Part 4 : After you are comfortable with basics of neural nets, it’s time to move to the next level. This is probably the best guide you would need to master RNN. RNN is a form of artificial neural network whose neurons send feedback signals to each other. I’d suggest you to follow the 4 parts religiously. It begins RNN from basics, followed by back propagation and its implementation.
Unreasonable Effectiveness of RNN: Consider this as an additional resource on RNN. If you are fond of seeking options, you might like to check this blog. It start with basic definition of RNN and goes all the way deep into building character models. This should help you give more hands on experience on implementing neural networks in various situations.
Backward Propogation Neural Network: Here you’ll find a simple explanation on the method of implementing backward propagation neural network. I’d suggest beginners to follow this blog and learn more about this concept. It will provide you a step by step approach for understanding neural networks deeply.
Deep Learning Tutorial by Stanford: This is by far the best tutorial/blog available on deep learning on internet. Having been recommended by many, it explains the complete science and mathematics behind every algorithm using easy to understand illustrations. This tutorial assumes basic knowledge of machine learning. Therefore, I’d suggest you to start with this tutorial after finishing Machine Learning course by Andrew Ng.
Videos
Complete Tutorial on Neural Networks : This complete playlist of neural network tutorials should suffice your learning appetite. There were numerous videos I found, but offered a comprehensive learning like this one.
Note: In order to quickly get started, I’d recommend you to participate in Facial keypoint Detection Kaggle competition. Though, this competition ended long time back, you can still participate and practice. Moreover, you’ll also find benchmark solution for this competition. Here is the solution: Practice – Neural Nets. Get Going!
Deep Learning Lectures: Here is a complete series of lectures on Deep Learning from University of Oxford 2015. The instructor is Nando de Freitas. This tutorials covers a wide range of topics from linear models, logistic regression, regularization to recurrent neural nets. Instead of rushing through these videos, I’d suggest you to devote good amount of time and develop concrete understanding of these concepts. Start from Lecture 1.
Introduction to Deep Learning with Python: After learning the theoretical aspects of these algorithm, it’s now time to practice them using Python. This ~1 hour video is highly recommended to practice deep learning in python using theano.
Deep Learning Summer School, Montreal 2015: Here are the videos from Deep Learning Summer School, Montreal 2015. These videos covers advanced topics in Deep Learning. Hence, I wouldn’t recommend them to beginners. However, people with knowledge of machine learning must watch them. These videos will take your deep learning intellect to a new level. Needless to say, they are FREE to access.
Also See: Top Youtube Videos on Machine Learning, Deep Learning and Neural Networks
Research Papers
I could list here numerous paper published on Deep Learning, but that would have defeated the purpose. Hence, to highlight the best resources, I’ve listed some of the seminal papers in this field:
Deep Learning in Neural Networks
Learning Deep Architectures for AI
Deep Learning of Representations: Looking Forward
Gradient based training for Deep Architechture
End Notes
By now, I’m sure you have a lot of work carved out for yourself. I found them intimidating initially, but these videos and blogs totally helped me to regain my confidence. As said above, these are free resources and can be accessible from anywhere. If you are a beginner, I’d recommend you to start with Machine Learning course by Andrew Ng and read through blogs too.
I’ve tried to provide the best possible resources available on these topics at present. As mentioned before, I am not an expert on neural networks and machine learning (yet)! So it is quite possible that I missed out on some useful resource. Did I miss out any useful resource? May be! Please share your views / suggestions in the comments section below.
Practical Guide to implementing Neural Networks in Python (using Theano)
By
Source: http://www.analyticsvidhya.com/blog/2016/04/neural-networks-python-theano/
Introduction
In my last article, I discussed the fundamentals of deep learning, where I explained the basic working of a artificial neural network. If you’ve been following this series, today we’ll become familiar with practical process of implementing neural network in Python (using Theano package).
I found various other packages also such as Caffe, Torch, TensorFlow etc to do this job. But, Theano is no less than and satisfactorily execute all the tasks. Also, it has multiple benefits which further enhances the coding experience in Python.
In this article, I’ll provide a comprehensive practical guide to implement Neural Networks using Theano. If you are here for just python codes, feel free to skip the sections and learn at your pace. And, if you are new to Theano, I suggest you to follow the article sequentially to gain complete knowledge.
Note:
- This article is best suited for users with knowledge of neural network & deep learning.
- If you don’t know python, start here.
- If you don’t know deep learning, start here.

Table of Contents
- Theano Overview
- Implementing Simple expressions
- Theano Variable Types
- Theano Functions
- Modeling a Single Neuron
- Modeling a Two-Layer Networks
1. Theano Overview
In short, we can define Theano as:
- A programming language which runs on top of Python but has its own data structure which are tightly integrated with numpy
- A linear algebra compiler with defined C-codes at the backend
- A python package allowing faster implementation of mathematical expressions
As popularly known, Theano was developed at the University of Montreal in 2008. It is used for defining and evaluating mathematical expressions in general.
Theano has several features which optimize the processing time of expressions. For instance it modifies the symbolic expressions we define before converting them to C codes. Examples:
- It makes the expressions faster, for instance it will change { (x+y) + (x+y) } to { 2*(x+y) }
- It makes expressions more stable, for instance it will change { exp(a) / exp(a).sum(axis=1) } to { softmax(a) }
Below are some powerful advantages of using Theano:
- It defines C-codes for different mathematical expressions.
- The implementations are much faster as compared to some of the python’s default implementations.
- Due to fast implementations, it works well in case of high dimensionality problems.
- It allows GPU implementation which works blazingly fast specially for problems like deep learning.
Let’s now focus on Theano (with example) and try to understand it as a programming language.
2. Implementing Simple Expressions
Lets start by implementing a simple mathematical expression, say a multiplication in Theano and see how the system works. In later sections, we will take a deep dive into individual components. The general structure of a Theano code works in 3 steps:
- Define variables/objects
- Define a mathematical expression in the form of a function
- Evaluate expressions by passing values
Lets look at the following code for simply multiplying 2 numbers:
Step 0: Import libraries
import numpy as np import theano.tensor as T from theano import function
Here, we have simply imported 2 key functions of theano – tensor and function.
Step 1: Define variables
a = T.dscalar('a')
b = T.dscalar('b')
Here 2 variables are defined. Note that we have used Theano tensor object type here. Also, the arguments passed to dscalar function are just name of tensors which are useful while debugging. They code will work even without them.
Step 2: Define expression
c = a*b f = function([a,b],c)
Here we have defined a function f which has 2 arguments:
- Inputs [a,b]: these are inputs to system
- Output c: this has been previously defined
Step 3: Evaluate Expression
f(1.5,3)
![]()
Now we are simply calling the function with the 2 inputs and we get the output as a multiple of the two. In short, we saw how we can define mathematical expressions in Theano and evaluate them. Before we go into complex functions, lets understand some inherent properties of Theano which will be useful in building neural networks.
3. Theano Variable Types
Variables are key building blocks of any programming language. In Theano, the objects are defined as tensors. A tensor can be understood as a generalized form of a vector with dimension t. Different dimensions are analogous to different types:
- t = 0: scalar
- t = 1: vector
- t = 2: matrix
- and so on..
Watch this interesting video to get a deeper level of intuition into vectors and tensors.
These variables can be defined similar to our definition of ‘dscalar’ in the above code. The various keywords for defining variables are:
- byte: bscalar, bvector, bmatrix, brow, bcol, btensor3, btensor4
- 16-bit integers: wscalar, wvector, wmatrix, wrow, wcol, wtensor3, wtensor4
- 32-bit integers: iscalar, ivector, imatrix, irow, icol, itensor3, itensor4
- 64-bit integers: lscalar, lvector, lmatrix, lrow, lcol, ltensor3, ltensor4
- float: fscalar, fvector, fmatrix, frow, fcol, ftensor3, ftensor4
- double: dscalar, dvector, dmatrix, drow, dcol, dtensor3, dtensor4
- complex: cscalar, cvector, cmatrix, crow, ccol, ctensor3, ctensor4
Now you understand that we can define variables with different memory allocations and dimensions. But this is not an exhaustive list. We can define dimensions higher than 4 using a generic TensorType class. You’ll find more details here.
Please note that variables of these types are just symbols. They don’t have a fixed value and are passed into functions as symbols. They only take values when a function is called. But, we often need variables which are constants and which we need not pass in all the functions. For this Theano provides shared variables. These have a fixed value and are not of the types discussed above. They can be defined as numpy data types or simple constants.
Lets take an example. Suppose, we initialize a shared variable as 0 and use a function which:
- takes an input
- adds the input to the shared variable
- returns the square of shared variable
This can be done as:
from theano import shared
x = T.iscalar('x')
sh = shared(0)
f = function([x], sh**2, updates=[(sh,sh+x)])
Note that here function has an additional argument called updates. It has to be a list of lists or tuples, each containing 2 elements of form (shared_variable, updated_value). The output for 3 subsequent runs is:

You can see that for each run, it returns the square of the present value, i.e. the value before updating. After the run, the value of shared variable gets updated. Also, note that shared variables have 2 functions “get_value()” and “set_value()” which are used to read and modify the value of shared variables.
4. Theano Functions
Till now we saw the basic structure of a function and how it handles shared variables. Lets move forward and discuss couple more things we can do with functions:
Return Multiple Values
We can return multiple values from a function. This can be easily done as shown in following example:
a = T.dscalar('a')
f = function([a],[a**2, a**3])
f(3)
![]()
We can see that the output is an array with the square and cube of the number passed into the function.
Computing Gradients
Gradient computation is one of the most important part of training a deep learning model. This can be done easily in Theano. Let’s define a function as the cube of a variable and determine its gradient.
x = T.dscalar('x')
y = x**3
qy = T.grad(y,x)
f = function([x],qy)
f(4)
This returns 48 which is 3x2 for x=4. Lets see how Theano has implemented this derivative using the pretty-print feature as following:
from theano import pp #pretty-print print(pp(qy))
![]()
In short, it can be explained as: fill(x3,1)*3*x3-1 You can see that this is exactly the derivative of x3. Note that fill(x3,1) simply means to make a matrix of same shape as x3 and fill it with 1. This is used to handle high dimensionality input and can be ignored in this case.
We can use Theano to compute Jacobian and Hessian matrices as well which you can find here.
There are various other aspects of Theano like conditional and looping constructs. You can go into further detail using following resources:
5. Modeling a Single Neuron
Lets start by modeling a single neuron.
Note that I will take examples from my previous article on neuron networks here. If you wish to go in the detail of how these work, please read this article. For modeling a neuron, lets adopt a 2 stage process:
- Implement Feed Forward Pass
- take inputs and determine output
- use the fixed weights for this case
- Implement Backward Propagation
- calculate error and gradients
- update weights using gradients
Lets implement an AND gate for this purpose.
Feed Forward Pass
An AND gate can be implemented as:
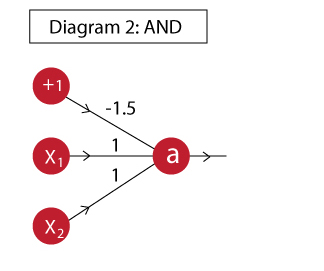
Now we will define a feed forward network which takes inputs and uses the shown weights to determine the output. First we will define a neuron which computes the output a.
import theano
import theano.tensor as T
from theano.ifelse import ifelse
import numpy as np
#Define variables:
x = T.vector('x')
w = T.vector('w')
b = T.scalar('b')
#Define mathematical expression:
z = T.dot(x,w)+b
a = ifelse(T.lt(z,0),0,1)
neuron = theano.function([x,w,b],a)
I have simply used the steps we saw above. If you are not sure how this expression works, please refer to the neural networks article I have referred above. Now let’s test out all values in the truth table and see if the AND function has been implemented as desired.
#Define inputs and weights
inputs = [
[0, 0],
[0, 1],
[1, 0],
[1, 1]
]
weights = [ 1, 1]
bias = -1.5
#Iterate through all inputs and find outputs:
for i in range(len(inputs)):
t = inputs[i]
out = neuron(t,weights,bias)
print 'The output for x1=%d | x2=%d is %d' % (t[0],t[1],out)

Note that, in this case we had to provide weights while calling the function. However, we will be required to update them while training. So, its better that we define them as a shared variable. The following code implements w as a shared variable. Try this out and you’ll get the same output.
import theano
import theano.tensor as T
from theano.ifelse import ifelse
import numpy as np
#Define variables:
x = T.vector('x')
w = theano.shared(np.array([1,1]))
b = theano.shared(-1.5)
#Define mathematical expression:
z = T.dot(x,w)+b
a = ifelse(T.lt(z,0),0,1)
neuron = theano.function([x],a)
#Define inputs and weights
inputs = [
[0, 0],
[0, 1],
[1, 0],
[1, 1]
]
#Iterate through all inputs and find outputs:
for i in range(len(inputs)):
t = inputs[i]
out = neuron(t)
print 'The output for x1=%d | x2=%d is %d' % (t[0],t[1],out)
Now the feedforward step is complete.
Backward Propagation
Now we have to modify the above code and perform following additional steps:
- Determine the cost or error based on true output
- Determine gradient of node
- Update the weights using this gradient
Lets initialize the network as follow:
#Gradient
import theano
import theano.tensor as T
from theano.ifelse import ifelse
import numpy as np
from random import random
#Define variables:
x = T.matrix('x')
w = theano.shared(np.array([random(),random()]))
b = theano.shared(1.)
learning_rate = 0.01
#Define mathematical expression:
z = T.dot(x,w)+b
a = 1/(1+T.exp(-z))
Note that, you will notice a change here as compared to above program. I have defined x as a matrix here and not a vector. This is more of a vectorized approach where we will determine all the outputs together and find the total cost which is required for determining the gradients.
You should also keep in mind that I am using the full-batch gradient descent here, i.e. we will use all training observations to update the weights.
Let’s determine the cost as follows:
a_hat = T.vector('a_hat') #Actual output
cost = -(a_hat*T.log(a) + (1-a_hat)*T.log(1-a)).sum()
In this code, we have defined a_hat as the actual observations. Then we determine the cost using a simple logistic cost function since this is a classification problem. Now lets compute the gradients and define a means to update the weights.
dw,db = T.grad(cost,[w,b])
train = function(
inputs = [x,a_hat],
outputs = [a,cost],
updates = [
[w, w-learning_rate*dw],
[b, b-learning_rate*db]
]
)
In here, we are first computing gradient of the cost w.r.t. the weights for inputs and bias unit. Then, the train function here does the weight update job. This is an elegant but tricky approach where the weights have been defined as shared variables and the updates argument of the function is used to update them every time a set of values are passed through the model.
#Define inputs and weights
inputs = [
[0, 0],
[0, 1],
[1, 0],
[1, 1]
]
outputs = [0,0,0,1]
#Iterate through all inputs and find outputs:
cost = []
for iteration in range(30000):
pred, cost_iter = train(inputs, outputs)
cost.append(cost_iter)
#Print the outputs:
print 'The outputs of the NN are:'
for i in range(len(inputs)):
print 'The output for x1=%d | x2=%d is %.2f' % (inputs[i][0],inputs[i][1],pred[i])
#Plot the flow of cost:
print '\nThe flow of cost during model run is as following:'
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(cost)

Here we have simply defined the inputs, outputs and trained the model. While training, we have also recorded the cost and its plot shows that our cost reduced towards zero and then finally saturated at a low value. The output of the network also matched the desired output closely. Hence, we have successfully implemented and trained a single neuron.
6. Modeling a Two-Layer Neural Network
I hope you have understood the last section. If not, please do read it multiple times and proceed to this section. Along with learning Theano, this will enhance your understanding of neural networks on the whole.
Lets consolidate our understanding by taking a 2-layer example. To keep things simple, I’ll take the XNOR example like in my previous article. If you wish to explore the nitty-gritty of how it works, I recommend reading the previous article.
The XNOR function can be implemented as:
As a reminder, the truth table of XNOR function is:

Now we will directly implement both feed forward and backward at one go.
Step 1: Define variables
import theano
import theano.tensor as T
from theano.ifelse import ifelse
import numpy as np
from random import random
#Define variables:
x = T.matrix('x')
w1 = theano.shared(np.array([random(),random()]))
w2 = theano.shared(np.array([random(),random()]))
w3 = theano.shared(np.array([random(),random()]))
b1 = theano.shared(1.)
b2 = theano.shared(1.)
learning_rate = 0.01
In this step we have defined all the required variables as in the previous case. Note that now we have 3 weight vectors corresponding to each neuron and 2 bias units corresponding to 2 layers.
Step 2: Define mathematical expression
a1 = 1/(1+T.exp(-T.dot(x,w1)-b1)) a2 = 1/(1+T.exp(-T.dot(x,w2)-b1)) x2 = T.stack([a1,a2],axis=1) a3 = 1/(1+T.exp(-T.dot(x2,w3)-b2))
Here we have simply defined mathematical expressions for each neuron in sequence. Note that here an additional step was required where x2 is determined. This is required because we want the outputs of a1 and a2 to be combined into a matrix whose dot product can be taken with the weights vector.
Lets explore this a bit further. Both a1 and a2 would return a vector with 4 units. So if we simply take an array [a1, a2] then we’ll obtain something like [ [a11,a12,a13,a14], [a21,a22,a23,a24] ]. However, we want this to be [ [a11,a21], [a12,a22], [a13,a23], [a14,a24] ]. The stacking function of Theano does this job for us.
Step 3: Define gradient and update rule
a_hat = T.vector('a_hat') #Actual output
cost = -(a_hat*T.log(a3) + (1-a_hat)*T.log(1-a3)).sum()
dw1,dw2,dw3,db1,db2 = T.grad(cost,[w1,w2,w3,b1,b2])
train = function(
inputs = [x,a_hat],
outputs = [a3,cost],
updates = [
[w1, w1-learning_rate*dw1],
[w2, w2-learning_rate*dw2],
[w3, w3-learning_rate*dw3],
[b1, b1-learning_rate*db1],
[b2, b2-learning_rate*db2]
]
)
This is very similar to the previous case. The key difference being that now we have to determine the gradients of 3 weight vectors and 2 bias units and update them accordingly.
Step 4: Train the model
inputs = [
[0, 0],
[0, 1],
[1, 0],
[1, 1]
]
outputs = [1,0,0,1]
#Iterate through all inputs and find outputs:
cost = []
for iteration in range(30000):
pred, cost_iter = train(inputs, outputs)
cost.append(cost_iter)
#Print the outputs:
print 'The outputs of the NN are:'
for i in range(len(inputs)):
print 'The output for x1=%d | x2=%d is %.2f' % (inputs[i][0],inputs[i][1],pred[i])
#Plot the flow of cost:
print '\nThe flow of cost during model run is as following:'
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(cost)

We can see that our network has successfully learned the XNOR function. Also, the cost of the model has reduced to reasonable limit. With this, we have successfully implemented a 2-layer network.
End Notes
In this article, we understood the basics of Theano package in Python and how it acts as a programming language. We also implemented some basic neural networks using Theano. I am sure that implementing Neural Networks on Theano will enhance your understanding of NN on the whole.
If hope you have been able to follow till this point, you really deserve a pat on your back. I can understand that Theano is not a traditional plug and play system like most of sklearn’s ML models. But the beauty of neural networks lies in their flexibility and an approach like this will allow you a high degree of customization in models. Some high-level wrappers of Theano do exist like Keras and Lasagne which you can check out. But I believe knowing the core of Theano will help you in using them.
Python Libraries Artificial Neural Networks (ANNs) +3 What is the best neural network library for Python?
DeepMind成员、谷歌资深员工:神经网络序列学习突破及发展
2016-05-02
文章来源:O’Reilly 报告《The Future of Machine Intelligence)
作者:David Beyer
题目:Oriol : Sequence-to-Sequence Machine Learning
下载: future-of-machine-intelligence
【新智元导读】谷歌CEO在给投资人的信中写道谷歌搜索将更具有情景意识,其关键技术自然是深度学习。本文中,谷歌资深员工、DeepMind 成员 Oriol Vinyals 全面剖析神经网络序列学习的优势、瓶颈及解决方案。他指出机器翻译实质上是基于序列的深度学习问题,其团队希望用机器学习替代启发式算法,最后推测机器阅读并理解文本将在未来几年实现。
文章来源:O’Reilly 报告《The Future of Machine Intelligence)
作者:David Beyer
题目:Oriol Vinyals: Sequence-to-Sequence Machine Learning
关注新智元公众号,回复“0502”下载报告全文
受访者 Oriol Vinyals 是 Google 的研究科学家,在 DeepMind 团队工作,曾前在 Google Brain 团队工作。他在加州大学伯克利分校拿到 EECS 博士学位,在加州大学圣地亚哥分校拿到硕士学位。
虽然很强大,序列到序列的学习方法也受到一些因素的制约,包括计算能力。长短期记忆(LSTM)在推动该领域前进方面作了很大贡献。
除了图像和文本理解,深度学习模型可以学会为一些著名的算法难题“编写”解决方案,其中包括邮差问题(Salesman Problem)。
【O’Reilly】让我们先了解一下你的背景吧。
【Oriol Vinyals】我来自西班牙巴塞罗那,在那里我完成了数学和通信工程的本科学习。很早,我就知道自己想要到美国学习 AI。我在卡耐基梅隆大学待了9个月,在那里我完成了本科毕业论文。之后我在加州大学圣地亚哥分校拿到硕士学位,然后 2009年在伯克利拿到博士学位。
读博期间,在 Google 实习时,我遇到了 Geoffrey Hinton 并和他一起工作;这段经历催化了我对深度学习的兴趣。加上我在微软和 Google 愉快的实习经历,当时我便下定决心要在产业界工作。2013 年我全职加入 Google。我起初对语音识别和优化 (重点放在自然语言处理和理解上) 有着浓厚的兴趣,后来转到使用深度学习解决这些以及别的问题这方面,包括最近基于数据来让算法自动学习的工作。
【O’Reilly】能不能谈一下你的关注点的变化,既然你离开了语言识别领域。现在最让你兴奋的是哪些领域?
【Oriol Vinyals】我的语言识别背景激发了我对序列的兴趣。最近,Ilya Sutskever, Quoc Le,还有我发表了一篇文章,是关于序列到序列映射的,可以使用循环神经网络(recurrent neural net) 进行从法语到英语的机器翻译。
作为背景,监督学习在输入和输出是矢量的情形下取得了成功。往这些经典的模型输入图片,可以输出相应的类别标签。直到不久前,我们还不能通过输入图片就得到一个单词序列作为对这幅图片的描述。目前的快速进展是得益于可以获取带有图片描述的高质量数据集 (MSCOCO),以及与此并行的循环神经网络的复兴。
我们的工作把机器翻译问题重塑为基于序列的深度学习问题。结果表明深度学习可以把英语的单词序列映射为西班牙语的单词序列。由于深度学习令人吃惊的能力,我们可以相当快地达到领域前沿水平。这些结果本身暗示了新的应用,比如,自动把视频提炼成四个描述性句子。
【O’Reilly】序列到序列这种方法在什么地方工作得不好?
【Oriol Vinyals】假设你要把一个英语句子翻译成法语。你可以使用一个巨大的政治言论和辩论语料库作为训练数据。应用得当的话,你可以把政治言论转化为任何别的语言。但是,当你试图把——比如说——莎士比亚式的英语——翻译成法语的时候,你会遇到问题。这种领域切换对深度学习方法压力比较大,而传统机器翻译系统是基于规则的,这让它们能适应这种切换。
还有更多的难点。当序列长度超过一定值时,我们缺乏相应的计算能力。当前的模型可以把长度为 200 的序列与对应的同样长度的序列匹配。当序列变长,运行时间也变长。虽然目前我们被局限于相对较短的文档,我相信随着时间推移这个限制会越来越宽松。正如 GPU 压缩了大而复杂的模型的运行时间,内存和计算能力的提高会让可计算的序列越来越长。
除了计算的瓶颈,更长的序列还带来了有趣的数学问题。若干年前 Hochreiter 引入了梯度消失的概念。当你阅读数千个单词,你很容易忘掉三千个单词前的信息;如果不记得第三章的关键情节转换,(小说的) 结局就失去意义。从结果上讲,挑战来自记忆。循环神经网络一般能记住 10 到 15 个词。但如果你把一个矩阵乘 15 次,输出会收缩到 0。换句话说,梯度消失,学习变得不可能。
这个问题的一种重要解决方案依赖于长短期记忆 (LSTM)。这种结构对循环神经网络做了聪明的修改,让它们能记住远超正常极限的东西。我见过能记住 300 到 400 个词的 LSTM。虽然已经相当长了,这样的增长只是个开始,以后的神经网络将能处理日常生活规模的文本。
退一步讲,近几年我们看到出现了一些处理记忆问题的模型。我个人尝试过添加这种记忆到神经网络:与其把所有东西塞进循环神经网络的隐含态,记忆让你回忆起之前见过的词,从而帮助解决手头的优化任务。虽然这些年进展迅速,更深层的、关于知识表达究竟意味着什么这一挑战仍然存在,并且其本身仍旧是一个开放问题。尽管如此,我相信接下来我们会看到沿着这些方向的重大进展。
【O’Reilly】让我们换个话题,谈谈你在算法生成方面的工作。你能不能讲讲这些努力背后的历史和动机?
【Oriol Vinyals】一个展示监督学习能力的经典练习涉及到把一些给定点分割为不同类别:这是 A 类,这是 B 类,等等。XOR (异或) (the“exclusive or” logical connective) 问题特别有教益。目标是要学会异或操作,也就是,给定两个二进制位作为输入,学习正确的输出。精确地讲,这涉及到两个位也就是四个实例:00,01,10,11。对于这些例子,输出是 0,1,1,0。这个问题不是线性模型能解决的,但深度学习可以。即便如此,目前计算能力的限制排除了更复杂的问题。
最近,Wojciech Zaremba (我们组的一个实习生) 发表了一篇文章,标题是“Learningto Execute”,描述了一个基于循环神经网络的从 Python 程序到执行这些程序的结果的映射。这个模型可以仅仅通过阅读源代码来预测 Python 程序的结果。这个问题虽然看起来简单,提供了一个良好开端。于是我把注意力转向一个 NP-hard 问题。
我们考虑的是一个高度复杂且资源需求高的方法,用来求解经过所有点的最短路径的问题,也就是著名的邮差问题。这个问题从提出开始,就吸引了大量解法;人们发明了各种启发式算法,在效率和精度之间求得平衡。在我们的情形,我们研究了深度学习系统是否能仅仅基于训练数据推断出与已有文献比肩的启发式算法。
出于效率的考虑,我们只考虑 10 个城市,而不是常见的10000 或 100000 个。我们的训练集输入城市位置,输出最短路径。就这样。我们不想让网络知晓任何别的关于这个问题的假设。
成功的神经网络应该能再现遍历所有点且最小化路程的行为。事实上,在一个可以称作奇迹的时刻,我们发现它能做到。
我应该补充一下,输出可能不是最优,因为毕竟是概率性的;但这是个好的开始。我们希望把这个方法应用到一些新问题。目标不是为了替换现有的、人工编码的解决方案,而是,我们要用机器学习代替启发式算法。
【O’Reilly】这会最终让我们成为更好的程序员吗?
【Oriol Vinyals】比如在编程竞赛中。开始是一段问题陈述,用直白的英语写:“在这个程序中,你需要找出 A,B,C,在 X,Y,以及 Z 的前提下。” 你编码你的解决方案,然后在服务器上测试。与此不同的是,想象一下,一个神经网络读入这样一个自然语言写的问题陈述,然后学到一个至少能给出近似解的算法,甚至能给出精确解。这个图景可能听起来太遥远。记住,仅仅几年前,读入 Python 程序然后输出答案也是听起来相当不靠谱的。
【O’Reilly】你怎么看待接下来五年你的工作会如何进展?最大的未解决问题有哪些?
【Oriol Vinyals】也许五年的时间有点紧,但机器阅读并理解一本书这样的事不会离我们很远。类似地,我们可以预期看到机器通过从数据学习来回答问题,而不是基于给定的规则集合。现在如果我问你一个问题,你打开 Google 开始搜索;几次尝试后你可能得到答案。跟你一样,机器应该能返回一个答案作为对某个问题的响应。我们已经有沿着这个方向基于紧凑数据集的模型。更往前的挑战是深刻的:你如何区分正确和错误的答案?如何量化正确和错误?这些以及别的重要问题决定未来研究的进程。
谷歌搜索算法如何排名医疗广告?
2016-05-02
【新智元导读】青年魏则西的不幸病逝激起了国内公众对搜索引擎虚假医疗网络广告问题的热议。提到搜索引擎,必须想到谷歌,那么谷歌是如何处理医疗广告的呢,答案是使用机器学习的RankBrain算法。
青年魏则西的不幸病逝,激起了国内公众对搜索引擎虚假医疗网络广告问题的热议。根据《商业价值》微信公众号今日文章《谷歌也曾涉足医疗广告,美国司法是如何监管的呢?》,可以发现在谷歌搜索“滑膜肉瘤”也会出医疗广告,但都有明显的“Ad”标识。同时,与百度相比,谷歌的付费广告并不影响排名。
此外,《商业价值》文中提到,根据谷歌的搜索广告政策,要投放药品广告需要获得 FDA 以及美国药房理事会(NABP)认证。也就是说,只有获得政府审批的正规网上药店、药品与治疗才能在网站投放药品类广告。同时,谷歌的自动广告过滤机制,在很大程度上也能有效杜绝虚假医疗广告出现。根据谷歌发布的报告,他们 2015 年总计预先屏蔽了 7.8 亿条违规广告,封杀 21.4 万家广告商,其中包括 1250 万条违规的医疗和药品广告,涉及药品未获批准或者虚假误导性宣传等原因。
据统计,每天向 Google 提交的查询中有约 15% 是其未曾见过的。公司的资深研究科学家 Greg Corrado 透露,为了更好回答这些问题,Google 利用了 RankBrain 来将海量的书面语嵌入到计算机可以理解的向量里面。
如果 RankBrain 看到自己不熟悉的单词或短语,它会去猜测其类似的意思并对结果进行相应过滤,从而有效地处理一些从未见过的搜索查询。比方说 RankBrain 能够有效回答 “What’ s the title of the consumer at the highest level of a food chain?(食物链当中最高级的消费者的头衔叫做什么?)” 这样的问题。
对于 Google 的搜索处理机制来说,RankBrain 只是为其搜索算法提供输入的数百个信号之一,但这种信号跟别的信号的不同之处在于它懂得学习,而别的只是别人在信息获取中的发现和洞察。Google 内部曾让做算法的工程师人工去猜测搜索算法会选择哪个页面作为排名第一的结果,其准确率为 70%,然后 RankBrain 去做了同样的事情,准确率达到了 80%,超过了做算法的工程师的平均水平。
随着时间的推移,RankBrain 可能能够处理越来越多的当前通过手写代码分析来改善 Google 算法的各种各样的信号。Google 的各项业务也会发展地越来越智能。机器学习将会以各种有意义的方式整合进 Google 的搜索引擎中。Google 这所有的举动将会继续保持其搜索引擎的领头地位。
RankBrain 是 Google 蜂鸟搜索算法的一部分。蜂鸟是整个搜索算法,就好比车里面有个引擎。引擎本身可能由许多部分组成,比如滤油器、燃油泵、散热器等。同理,蜂鸟也由多个部分组成,RankBrain就是其中一个组成部分。
蜂鸟同时包含其他的部分,这些名字对 SEO圈的人来说已经耳熟能详了,比如 Panda、 Penguin 和 Payday 用于垃圾邮件过滤, Pigeon 用于优化本地结果, Top Heavy 用于给广告太多的页面降级,Mobile Friendly 用于给移动友好型页面加分,Pirate 用于打击版权侵犯。
Google 用于排序的“信号”是什么?
Google 使用信号来决定如何为网页排序。比如,它会读取网页上的词语,那么词语就是一个信号。如果某些词语是粗体,那么这又是一个值得注意的信号。计算的结果作为PageRank的一部分,给一个网页设定一个PageRank分数,这作为一个信号。如果一张网页被检测到是移动友好型的,那么这又会成为一个信号。所有的这些信号都由蜂鸟算法中的各个部分处理,最后决定针对不同搜索返回哪些网页。
一共有多少种信号?
Google 称进行评估的主要排序信号大约有 200多种,反过来, 可能有上万种变种信号或者子信号。如果你想有一个更直观的排序信号向导,来看看 Google SEO成功因素元素周期表:
RankBrain到底做什么?
从与 Google 的来往电子邮件之中,RankBrain 主要用于翻译人们可能不清楚该输入什么确切词语的搜索词条。
Google 很早就找到不根据具体词条搜索页面的方式。比如,许多年前,如果你输入“鞋”(shoe), Google 可能不会找到那些有“鞋”(shoes)的页面,因为从技术上来说这是两个不同的词汇,但是“stemming”使得 Google 变得更聪明,让引擎了解shoes的词根是shoe,就像“running”的词根是“run”。 Google 同样了解同义词,因此,如果你搜索“运动鞋”,它可能知道你想找“跑鞋”。它甚至有概念性的知识,知道哪些网页是关于“苹果”公司,哪些是关于水果“苹果”的。
参考资料:
http://mp.weixin.qq.com/s?__biz=MTA2MTMwNjYwMQ==&mid=2650693625&idx=1&sn=8ab532faa66e69cc447e250f58807dda&scene=1&srcid=0502LFwayyLBIMhASaZX4zrt#rd
10 种机器学习算法的要点
2015-10-24 伯乐在线
前言
谷歌董事长施密特曾说过:虽然谷歌的无人驾驶汽车和机器人受到了许多媒体关注,但是这家公司真正的未来在于机器学习,一种让计算机更聪明、更个性化的技术。
也许我们生活在人类历史上最关键的时期:从使用大型计算机,到个人电脑,再到现在的云计算。关键的不是过去发生了什么,而是将来会有什么发生。
工具和技术的民主化,让像我这样的人对这个时期兴奋不已。计算的蓬勃发展也是一样。如今,作为一名数据科学家,用复杂的算法建立数据处理机器一小时能赚到好几美金。但能做到这个程度可并不简单!我也曾有过无数黑暗的日日夜夜。
谁能从这篇指南里受益最多?
我今天所给出的,也许是我这辈子写下的最有价值的指南。
这篇指南的目的,是为那些有追求的数据科学家和机器学习狂热者们,简化学习旅途。这篇指南会让你动手解决机器学习的问题,并从实践中获得真知。我提供的是几个机器学习算法的高水平理解,以及运行这些算法的 R 和 Python 代码。这些应该足以让你亲自试一试了。

我特地跳过了这些技术背后的数据,因为一开始你并不需要理解这些。如果你想从数据层面上理解这些算法,你应该去别处找找。但如果你想要在开始一个机器学习项目之前做些准备,你会喜欢这篇文章的。
广义来说,有三种机器学习算法
1、 监督式学习
工作机制:这个算法由一个目标变量或结果变量(或因变量)组成。这些变量由已知的一系列预示变量(自变量)预测而来。利用这一系列变量,我们生成一个将输入值映射到期望输出值的函数。这个训练过程会一直持续,直到模型在训练数据上获得期望的精确度。监督式学习的例子有:回归、决策树、随机森林、K – 近邻算法、逻辑回归等。
2、非监督式学习
工作机制:在这个算法中,没有任何目标变量或结果变量要预测或估计。这个算法用在不同的组内聚类分析。这种分析方式被广泛地用来细分客户,根据干预的方式分为不同的用户组。非监督式学习的例子有:关联算法和 K – 均值算法。
3、强化学习
工作机制:这个算法训练机器进行决策。它是这样工作的:机器被放在一个能让它通过反复试错来训练自己的环境中。机器从过去的经验中进行学习,并且尝试利用了解最透彻的知识作出精确的商业判断。 强化学习的例子有马尔可夫决策过程。
常见机器学习算法名单
这里是一个常用的机器学习算法名单。这些算法几乎可以用在所有的数据问题上:
- 线性回归
- 逻辑回归
- 决策树
- SVM
- 朴素贝叶斯
- K最近邻算法
- K均值算法
- 随机森林算法
- 降维算法
- Gradient Boost 和 Adaboost 算法
1、线性回归
线性回归通常用于根据连续变量估计实际数值(房价、呼叫次数、总销售额等)。我们通过拟合最佳直线来建立自变量和因变量的关系。这条最佳直线叫做回归线,并且用 Y= a *X + b 这条线性等式来表示。
理解线性回归的最好办法是回顾一下童年。假设在不问对方体重的情况下,让一个五年级的孩子按体重从轻到重的顺序对班上的同学排序,你觉得这个孩子会怎么做?他(她)很可能会目测人们的身高和体型,综合这些可见的参数来排列他们。这是现实生活中使用线性回归的例子。实际上,这个孩子发现了身高和体型与体重有一定的关系,这个关系看起来很像上面的等式。
在这个等式中:
- Y:因变量
- a:斜率
- x:自变量
- b :截距
系数 a 和 b 可以通过最小二乘法获得。
参见下例。我们找出最佳拟合直线 y=0.2811x+13.9。已知人的身高,我们可以通过这条等式求出体重。
线性回归的两种主要类型是一元线性回归和多元线性回归。一元线性回归的特点是只有一个自变量。多元线性回归的特点正如其名,存在多个自变量。找最佳拟合直线的时候,你可以拟合到多项或者曲线回归。这些就被叫做多项或曲线回归。
Python 代码
#Import Library#Import other necessary libraries like pandas, numpy...fromsklearnimportlinear_model#Load Train and Test datasets#Identify feature and response variable(s) and values must be numeric and numpy arraysx_train=input_variables_values_training_datasetsy_train=target_variables_values_training_datasetsx_test=input_variables_values_test_datasets# Create linear regression objectlinear=linear_model.LinearRegression()# Train the model using the training sets and check scorelinear.fit(x_train, y_train)linear.score(x_train, y_train)#Equation coefficient and Intercept('Coefficient: n', linear.coef_)('Intercept: n', linear.intercept_)#Predict Outputpredicted=linear.predict(x_test)
R代码
#Load Train and Test datasets#Identify feature and response variable(s) and values must be numeric and numpy arraysx_train <- input_variables_values_training_datasetsy_train <- target_variables_values_training_datasetsx_test <- input_variables_values_test_datasetsx <- cbind(x_train,y_train)# Train the model using the training sets and check scorelinear <- lm(y_train ~ ., data = x)summary(linear)#Predict Outputpredicted= predict(linear,x_test)
2、逻辑回归
别被它的名字迷惑了!这是一个分类算法而不是一个回归算法。该算法可根据已知的一系列因变量估计离散数值(比方说二进制数值 0 或 1 ,是或否,真或假)。简单来说,它通过将数据拟合进一个逻辑函数来预估一个事件出现的概率。因此,它也被叫做逻辑回归。因为它预估的是概率,所以它的输出值大小在 0 和 1 之间(正如所预计的一样)。
让我们再次通过一个简单的例子来理解这个算法。
假设你的朋友让你解开一个谜题。这只会有两个结果:你解开了或是你没有解开。想象你要解答很多道题来找出你所擅长的主题。这个研究的结果就会像是这样:假设题目是一道十年级的三角函数题,你有 70%的可能会解开这道题。然而,若题目是个五年级的历史题,你只有30%的可能性回答正确。这就是逻辑回归能提供给你的信息。
从数学上看,在结果中,几率的对数使用的是预测变量的线性组合模型。
odds= p/ (1-p) = probability of event occurrence / probability of not event occurrenceln(odds) = ln(p/(1-p))logit(p) = ln(p/(1-p)) = b0+b1X1+b2X2+b3X3....+bkXk
在上面的式子里,p 是我们感兴趣的特征出现的概率。它选用使观察样本值的可能性最大化的值作为参数,而不是通过计算误差平方和的最小值(就如一般的回归分析用到的一样)。
现在你也许要问了,为什么我们要求出对数呢?简而言之,这种方法是复制一个阶梯函数的最佳方法之一。我本可以更详细地讲述,但那就违背本篇指南的主旨了。
Python代码
#Import Libraryfromsklearn.linear_modelimportLogisticRegression#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset# Create logistic regression objectmodel=LogisticRegression()# Train the model using the training sets and check scoremodel.fit(X, y)model.score(X, y)#Equation coefficient and Intercept('Coefficient: n', model.coef_)('Intercept: n', model.intercept_)#Predict Outputpredicted=model.predict(x_test)
R代码
x <- cbind(x_train,y_train)# Train the model using the training sets and check scorelogistic <- glm(y_train ~ ., data = x,family='binomial')summary(logistic)#Predict Outputpredicted= predict(logistic,x_test)
更进一步:
你可以尝试更多的方法来改进这个模型:
- 加入交互项
- 精简模型特性
- 使用正则化方法
- 使用非线性模型
3、决策树
这是我最喜爱也是最频繁使用的算法之一。这个监督式学习算法通常被用于分类问题。令人惊奇的是,它同时适用于分类变量和连续因变量。在这个算法中,我们将总体分成两个或更多的同类群。这是根据最重要的属性或者自变量来分成尽可能不同的组别。想要知道更多,可以阅读:简化决策树。
来源: statsexchange
在上图中你可以看到,根据多种属性,人群被分成了不同的四个小组,来判断 “他们会不会去玩”。为了把总体分成不同组别,需要用到许多技术,比如说 Gini、Information Gain、Chi-square、entropy。
理解决策树工作机制的最好方式是玩Jezzball,一个微软的经典游戏(见下图)。这个游戏的最终目的,是在一个可以移动墙壁的房间里,通过造墙来分割出没有小球的、尽量大的空间。
因此,每一次你用墙壁来分隔房间时,都是在尝试着在同一间房里创建两个不同的总体。相似地,决策树也在把总体尽量分割到不同的组里去。
更多信息请见:决策树算法的简化
Python代码
#Import Library#Import other necessary libraries like pandas, numpy...fromsklearnimporttree#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset# Create tree objectmodel=tree.DecisionTreeClassifier(criterion='gini')# for classification, here you can change the algorithm as gini or entropy (information gain) by default it is gini# model = tree.DecisionTreeRegressor() for regression# Train the model using the training sets and check scoremodel.fit(X, y)model.score(X, y)#Predict Outputpredicted=model.predict(x_test)
R语言
library(rpart)x <- cbind(x_train,y_train)# grow treefit <- rpart(y_train ~ ., data = x,method="class")summary(fit)#Predict Outputpredicted= predict(fit,x_test)
4、支持向量机
这是一种分类方法。在这个算法中,我们将每个数据在N维空间中用点标出(N是你所有的特征总数),每个特征的值是一个坐标的值。
举个例子,如果我们只有身高和头发长度两个特征,我们会在二维空间中标出这两个变量,每个点有两个坐标(这些坐标叫做支持向量)。
现在,我们会找到将两组不同数据分开的一条直线。两个分组中距离最近的两个点到这条线的距离同时最优化。
上面示例中的黑线将数据分类优化成两个小组,两组中距离最近的点(图中A、B点)到达黑线的距离满足最优条件。这条直线就是我们的分割线。接下来,测试数据落到直线的哪一边,我们就将它分到哪一类去。
更多请见:支持向量机的简化
将这个算法想作是在一个 N 维空间玩 JezzBall。需要对游戏做一些小变动:
- 比起之前只能在水平方向或者竖直方向画直线,现在你可以在任意角度画线或平面。
- 游戏的目的变成把不同颜色的球分割在不同的空间里。
- 球的位置不会改变。
Python代码
#Import Libraryfromsklearnimportsvm#Assumed you have, X (predictor)andY (target)fortraining datasetandx_test(predictor) of test_dataset# Create SVM classification objectmodel=svm.svc()# there is various option associated with it, this is simple for classification. You can refer link, for mo# re detail.# Train the model using the training sets and check scoremodel.fit(X, y)model.score(X, y)#Predict Outputpredicted=model.predict(x_test)
R代码
library(e1071)x <- cbind(x_train,y_train)# Fitting modelfit <-svm(y_train ~ ., data = x)summary(fit)#Predict Outputpredicted= predict(fit,x_test)
5、朴素贝叶斯
在预示变量间相互独立的前提下,根据贝叶斯定理可以得到朴素贝叶斯这个分类方法。用更简单的话来说,一个朴素贝叶斯分类器假设一个分类的特性与该分类的其它特性不相关。举个例子,如果一个水果又圆又红,并且直径大约是 3 英寸,那么这个水果可能会是苹果。即便这些特性互相依赖,或者依赖于别的特性的存在,朴素贝叶斯分类器还是会假设这些特性分别独立地暗示这个水果是个苹果。
朴素贝叶斯模型易于建造,且对于大型数据集非常有用。虽然简单,但是朴素贝叶斯的表现却超越了非常复杂的分类方法。
贝叶斯定理提供了一种从P(c)、P(x)和P(x|c) 计算后验概率 P(c|x) 的方法。请看以下等式:
在这里,
- P(c|x) 是已知预示变量(属性)的前提下,类(目标)的后验概率
- P(c) 是类的先验概率
- P(x|c) 是可能性,即已知类的前提下,预示变量的概率
- P(x) 是预示变量的先验概率
例子:让我们用一个例子来理解这个概念。在下面,我有一个天气的训练集和对应的目标变量“Play”。现在,我们需要根据天气情况,将会“玩”和“不玩”的参与者进行分类。让我们执行以下步骤。
步骤1:把数据集转换成频率表。
步骤2:利用类似“当Overcast可能性为0.29时,玩耍的可能性为0.64”这样的概率,创造 Likelihood 表格。
步骤3:现在,使用朴素贝叶斯等式来计算每一类的后验概率。后验概率最大的类就是预测的结果。
问题:如果天气晴朗,参与者就能玩耍。这个陈述正确吗?
我们可以使用讨论过的方法解决这个问题。于是 P(会玩 | 晴朗)= P(晴朗 | 会玩)* P(会玩)/ P (晴朗)
我们有 P (晴朗 |会玩)= 3/9 = 0.33,P(晴朗) = 5/14 = 0.36, P(会玩)= 9/14 = 0.64
现在,P(会玩 | 晴朗)= 0.33 * 0.64 / 0.36 = 0.60,有更大的概率。
朴素贝叶斯使用了一个相似的方法,通过不同属性来预测不同类别的概率。这个算法通常被用于文本分类,以及涉及到多个类的问题。
Python代码
#Import Libraryfromsklearn.naive_bayesimportGaussianNB#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset# Create SVM classification object model = GaussianNB() # there is other distribution for multinomial classes like Bernoulli Naive Bayes, Refer link# Train the model using the training sets and check scoremodel.fit(X, y)#Predict Outputpredicted=model.predict(x_test)
R代码
library(e1071)x <- cbind(x_train,y_train)# Fitting modelfit <-naiveBayes(y_train ~ ., data = x)summary(fit)#Predict Outputpredicted= predict(fit,x_test)
6、KNN(K – 最近邻算法)
该算法可用于分类问题和回归问题。然而,在业界内,K – 最近邻算法更常用于分类问题。K – 最近邻算法是一个简单的算法。它储存所有的案例,通过周围k个案例中的大多数情况划分新的案例。根据一个距离函数,新案例会被分配到它的 K 个近邻中最普遍的类别中去。
这些距离函数可以是欧式距离、曼哈顿距离、明式距离或者是汉明距离。前三个距离函数用于连续函数,第四个函数(汉明函数)则被用于分类变量。如果 K=1,新案例就直接被分到离其最近的案例所属的类别中。有时候,使用 KNN 建模时,选择 K 的取值是一个挑战。
更多信息:K – 最近邻算法入门(简化版)
我们可以很容易地在现实生活中应用到 KNN。如果想要了解一个完全陌生的人,你也许想要去找他的好朋友们或者他的圈子来获得他的信息。
在选择使用 KNN 之前,你需要考虑的事情:
- KNN 的计算成本很高。
- 变量应该先标准化(normalized),不然会被更高范围的变量偏倚。
- 在使用KNN之前,要在野值去除和噪音去除等前期处理多花功夫。
Python代码
#Import Libraryfromsklearn.neighborsimportKNeighborsClassifier#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset# Create KNeighbors classifier object modelKNeighborsClassifier(n_neighbors=6)# default value for n_neighbors is 5# Train the model using the training sets and check scoremodel.fit(X, y)#Predict Outputpredicted=model.predict(x_test)
R代码
library(knn)x <- cbind(x_train,y_train)# Fitting modelfit <-knn(y_train ~ ., data = x,k=5)summary(fit)#Predict Outputpredicted= predict(fit,x_test)
7、K 均值算法
K – 均值算法是一种非监督式学习算法,它能解决聚类问题。使用 K – 均值算法来将一个数据归入一定数量的集群(假设有 k 个集群)的过程是简单的。一个集群内的数据点是均匀齐次的,并且异于别的集群。
还记得从墨水渍里找出形状的活动吗?K – 均值算法在某方面类似于这个活动。观察形状,并延伸想象来找出到底有多少种集群或者总体。
K – 均值算法怎样形成集群:
- K – 均值算法给每个集群选择k个点。这些点称作为质心。
- 每一个数据点与距离最近的质心形成一个集群,也就是 k 个集群。
- 根据现有的类别成员,找出每个类别的质心。现在我们有了新质心。
- 当我们有新质心后,重复步骤 2 和步骤 3。找到距离每个数据点最近的质心,并与新的k集群联系起来。重复这个过程,直到数据都收敛了,也就是当质心不再改变。
如何决定 K 值:
K – 均值算法涉及到集群,每个集群有自己的质心。一个集群内的质心和各数据点之间距离的平方和形成了这个集群的平方值之和。同时,当所有集群的平方值之和加起来的时候,就组成了集群方案的平方值之和。
我们知道,当集群的数量增加时,K值会持续下降。但是,如果你将结果用图表来表示,你会看到距离的平方总和快速减少。到某个值 k 之后,减少的速度就大大下降了。在此,我们可以找到集群数量的最优值。
Python代码
#Import Library
fromsklearn.clusterimportKMeans#Assumed you have, X (attributes) for training data set and x_test(attributes) of test_dataset# Create KNeighbors classifier object modelk_means=KMeans(n_clusters=3, random_state=0)# Train the model using the training sets and check scoremodel.fit(X)#Predict Outputpredicted=model.predict(x_test)
8、随机森林
随机森林是表示决策树总体的一个专有名词。在随机森林算法中,我们有一系列的决策树(因此又名“森林”)。为了根据一个新对象的属性将其分类,每一个决策树有一个分类,称之为这个决策树“投票”给该分类。这个森林选择获得森林里(在所有树中)获得票数最多的分类。
每棵树是像这样种植养成的:
- 如果训练集的案例数是 N,则从 N 个案例中用重置抽样法随机抽取样本。这个样本将作为“养育”树的训练集。
- 假如有 M 个输入变量,则定义一个数字 m<<M。m 表示,从 M 中随机选中 m 个变量,这 m 个变量中最好的切分会被用来切分该节点。在种植森林的过程中,m 的值保持不变。
- 尽可能大地种植每一棵树,全程不剪枝。
若想了解这个算法的更多细节,比较决策树以及优化模型参数,我建议你阅读以下文章:
- 随机森林入门—简化版
- 将 CART 模型与随机森林比较(上)
- 将随机森林与 CART 模型比较(下)
- 调整你的随机森林模型参数
Python
#Import Libraryfromsklearn.ensembleimportRandomForestClassifier#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset# Create Random Forest objectmodel=RandomForestClassifier()# Train the model using the training sets and check scoremodel.fit(X, y)#Predict Outputpredicted=model.predict(x_test)
R代码
library(randomForest)x <- cbind(x_train,y_train)# Fitting modelfit <- randomForest(Species ~ ., x,ntree=500)summary(fit)#Predict Outputpredicted= predict(fit,x_test)
9、降维算法
在过去的 4 到 5 年里,在每一个可能的阶段,信息捕捉都呈指数增长。公司、政府机构、研究组织在应对着新资源以外,还捕捉详尽的信息。
举个例子:电子商务公司更详细地捕捉关于顾客的资料:个人信息、网络浏览记录、他们的喜恶、购买记录、反馈以及别的许多信息,比你身边的杂货店售货员更加关注你。
作为一个数据科学家,我们提供的数据包含许多特点。这听起来给建立一个经得起考研的模型提供了很好材料,但有一个挑战:如何从 1000 或者 2000 里分辨出最重要的变量呢?在这种情况下,降维算法和别的一些算法(比如决策树、随机森林、PCA、因子分析)帮助我们根据相关矩阵,缺失的值的比例和别的要素来找出这些重要变量。
想要知道更多关于该算法的信息,可以阅读《降维算法的初学者指南》。
Python代码
#Import Libraryfromsklearnimportdecomposition#Assumed you have training and test data set as train and test# Create PCA obeject pca= decomposition.PCA(n_components=k) #default value of k =min(n_sample, n_features)# For Factor analysis#fa= decomposition.FactorAnalysis()# Reduced the dimension of training dataset using PCAtrain_reduced=pca.fit_transform(train)#Reduced the dimension of test datasettest_reduced=pca.transform(test)#For more detail on this, please refer this link.
R Code
library(stats)pca <- princomp(train, cor = TRUE)train_reduced <- predict(pca,train)test_reduced <- predict(pca,test)
10、Gradient Boosting 和 AdaBoost 算法
当我们要处理很多数据来做一个有高预测能力的预测时,我们会用到 GBM 和 AdaBoost 这两种 boosting 算法。boosting 算法是一种集成学习算法。它结合了建立在多个基础估计值基础上的预测结果,来增进单个估计值的可靠程度。这些 boosting 算法通常在数据科学比赛如 Kaggl、AV Hackathon、CrowdAnalytix 中很有效。
更多:详尽了解 Gradient 和 AdaBoost
Python代码
#Import Libraryfromsklearn.ensembleimportGradientBoostingClassifier#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset# Create Gradient Boosting Classifier objectmodel=GradientBoostingClassifier(n_estimators=100, learning_rate=1.0, max_depth=1, random_state=0)# Train the model using the training sets and check scoremodel.fit(X, y)#Predict Outputpredicted=model.predict(x_test)
R code
library(caret)x <- cbind(x_train,y_train)# Fitting modelfitControl <- trainControl( method = "repeatedcv", number = 4, repeats = 4)fit <- train(y ~ ., data = x, method = "gbm", trControl = fitControl,verbose = FALSE)predicted= predict(fit,x_test,type= "prob")[,2]
结语GradientBoostingClassifier 和随机森林是两种不同的 boosting 树分类器。人们常常问起这两个算法之间的区别。
现在我能确定,你对常用的机器学习算法应该有了大致的了解。写这篇文章并提供 Python 和 R 语言代码的唯一目的,就是让你立马开始学习。
如果你想要掌握机器学习,那就立刻开始吧。做做练习,理性地认识整个过程,应用这些代码,并感受乐趣吧!
startup web developer
startup现招web developer,要求:
1.有extensive worldpress experience并且能非常熟练运用;
2.如果有subscription web的经历会非常好,
3.
4.entrepreneurial mind
这个职位是兼职flexible hours,远程操作,直接和CEO沟通。
邮件主题请注明web developer
