来源: 朱小厮
链接: http://blog.csdn.net/u013256816/article/details/50764532
Java 中的堆是 JVM 所管理的最大的一块内存空间,主要用于存放各种类的实例对象。
在 Java 中,堆被划分成两个不同的区域:新生代 ( Young )、老年代 ( Old )。新生代 ( Young ) 又被划分为三个区域:Eden、From Survivor、To Survivor。
这样划分的目的是为了使 JVM 能够更好的管理堆内存中的对象,包括内存的分配以及回收。
堆的内存模型大致为:
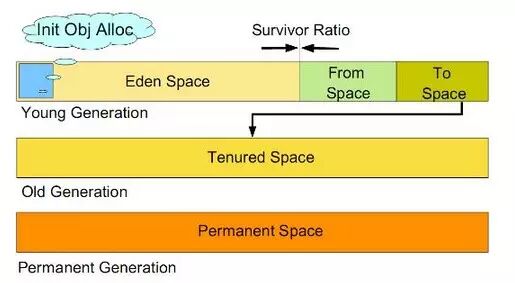
新生代:Young Generation,主要用来存放新生的对象。
老年代:Old Generation或者称作Tenured Generation,主要存放应用程序声明周期长的内存对象。
永久代:(方法区,不属于java堆,另一个别名为“非堆Non-Heap”但是一般查看PrintGCDetails都会带上PermGen区)是指内存的永久保存区域,主要存放Class和Meta的信息,Class在被 Load的时候被放入PermGen space区域. 它和和存放Instance的Heap区域不同,GC(Garbage Collection)不会在主程序运行期对PermGen space进行清理,所以如果你的应用会加载很多Class的话,就很可能出现PermGen space错误。
堆大小 = 新生代 + 老年代。其中,堆的大小可以通过参数 –Xms、-Xmx 来指定。
默认的,新生代 ( Young ) 与老年代 ( Old ) 的比例的值为 1:2 ( 该值可以通过参数 –XX:NewRatio 来指定 ),即:新生代 ( Young ) = 1/3 的堆空间大小。老年代 ( Old ) = 2/3 的堆空间大小。其中,新生代 ( Young ) 被细分为 Eden 和 两个 Survivor 区域,这两个 Survivor 区域分别被命名为 from 和 to,以示区分。
默认的,Edem : from : to = 8 : 1 : 1 ( 可以通过参数 –XX:SurvivorRatio 来设定 ),即: Eden = 8/10 的新生代空间大小,from = to = 1/10 的新生代空间大小。
JVM 每次只会使用 Eden 和其中的一块 Survivor 区域来为对象服务,所以无论什么时候,总是有一块 Survivor 区域是空闲着的。
因此,新生代实际可用的内存空间为 9/10 ( 即90% )的新生代空间。
回收方法区(附加补充)
很多人认为方法区(或者HotSpot虚拟机中的永久代[PermGen])是没有垃圾收集的,java虚拟机规范中确实说过可以不要求虚拟机在方法区实现垃圾收集,而且在方法去中进行垃圾收集的“性价比”一般比较低:在堆中,尤其是在新生代中,常规应用进行一次垃圾收集一般可以回收70%-95%的空间,而永久代的垃圾收集效率远低于此。
永久代的垃圾收集主要回收两部分内容:废弃的常量和无用的类。
1. 废弃的常量:回收废弃常量与回收java堆中的对象非常类似。以常量池字面量的回收为例,加入一个字符串“abc”已经进入了常量池中,但是当前系统没有任何一个String对象是叫做”abc”的,换句话说,就是有任何String对象应用常量池中的”abc”常量,也没有其他地方引用了这个字面量,如果这时发生内存回收,而且必要的话,这个“abc”常量就会被系统清理出常量池。常量池中的其他类(接口)、方法、字段的符号引用也与此类似。(注:jdk1.7及其之后的版本已经将常量池从永久代中移出)
2. 无用的类:类需要同时满足下面3个条件才能算是“无用的类”:
- 该类所有的实例都已经被回收,也就是java堆中不存在该类的任何实例。
- 加载该类的ClassLoader已经被回收
- 该类对应的java.lang.Class对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
虚拟机可以对满足上述3个条件的无用类进行回收,这里说的仅仅是”可以“,而并不和对象一样,不使用了就必然会回收。是否对类进行回收,HotSpot虚拟机提供了-Xnoclassgc(关闭CLASS的垃圾回收功能,就是虚拟机加载的类,即便是不使用,没有实例也不会回收。)参数进行控制。
在大量使用反射、动态代理、CGlib等ByteCode框架、动态生成JSP以及OSGi这类频繁自定义ClassLoader的场景都需要虚拟机具备类卸载的功能,以保证永久代不会溢出。
GC
Java 中的堆也是 GC 收集垃圾的主要区域。GC 分为两种:Minor GC、Full GC ( 或称为 Major GC )。
Minor GC 是发生在新生代中的垃圾收集动作,所采用的是复制算法。
新生代几乎是所有 Java 对象出生的地方,即 Java 对象申请的内存以及存放都是在这个地方。Java 中的大部分对象通常不需长久存活,具有朝生夕灭的性质。
当一个对象被判定为 “死亡” 的时候,GC 就有责任来回收掉这部分对象的内存空间。新生代是 GC 收集垃圾的频繁区域。
当对象在 Eden ( 包括一个 Survivor 区域,这里假设是 from 区域 ) 出生后,在经过一次 Minor GC 后,如果对象还存活,并且能够被另外一块 Survivor 区域所容纳( 上面已经假设为 from 区域,这里应为 to 区域,即 to 区域有足够的内存空间来存储 Eden 和 from 区域中存活的对象 ),则使用复制算法将这些仍然还存活的对象复制到另外一块 Survivor 区域 ( 即 to 区域 ) 中,然后清理所使用过的 Eden 以及 Survivor 区域 ( 即 from 区域 ),并且将这些对象的年龄设置为1,以后对象在 Survivor 区每熬过一次 Minor GC,就将对象的年龄 + 1,当对象的年龄达到某个值时 ( 默认是 15 岁,可以通过参数 -XX:MaxTenuringThreshold 来设定 ),这些对象就会成为老年代。
但这也不是一定的,对于一些较大的对象 ( 即需要分配一块较大的连续内存空间 ) 则是直接进入到老年代。虚拟机提供了一个-XX:PretenureSizeThreshold参数,令大于这个设置值的对象直接在老年代分配。这样做的目的是避免在Eden区及两个Survivor区之间发生大量的内存复制(新生代采用复制算法收集内存)。
为了能够更好的适应不同的程序的内存状况,虚拟机并不是永远地要求对象的年龄必须达到了MaxTenuringThreshold才能晋升老年代,如果在Survivor空间中相同年龄所有对象大小的总和大于Survivor空间的一半,年龄大于或等于该年龄的对象可以直接进入老年代,无需等到MaxTenuringThreshold中要求的年龄。
Full GC 是发生在老年代的垃圾收集动作,所采用的是“标记-清除”或者“标记-整理”算法。
现实的生活中,老年代的人通常会比新生代的人 “早死”。堆内存中的老年代(Old)不同于这个,老年代里面的对象几乎个个都是在 Survivor 区域中熬过来的,它们是不会那么容易就 “死掉” 了的。因此,Full GC 发生的次数不会有 Minor GC 那么频繁,并且做一次 Full GC 要比进行一次 Minor GC 的时间更长。
在发生MinorGC之前,虚拟机会先检查老年代最大可用的连续空间是否大于新生代所有对象总空间,如果这个条件成立,那么MinorGC可以确保是安全的。如果不成立,则虚拟机会查看HandlePromotionFailure设置值是否允许担保失败。如果允许,那么会继续检查老年代最大可用的连续空间是否大于历次晋升到老年代对象的平均大小,如果大于,将尝试这进行一次MinorGC,尽管这次MinorGC是有风险的;如果小于,或者HandlePromptionFailure设置不允许冒险,那这是也要改为进行一次FullGC.
另外,标记-清除算法收集垃圾的时候会产生许多的内存碎片 ( 即不连续的内存空间 ),此后需要为较大的对象分配内存空间时,若无法找到足够的连续的内存空间,就会提前触发一次 GC 的收集动作。
GC日志
首先看一下如下代码:
package jvm;
public class PrintGCDetails
{
public static void main(String[] args)
{
Object obj = new Object();
System.gc();
System.out.println();
obj = new Object();
obj = new Object();
System.gc();
System.out.println();
}
}
设置JVM参数为-XX:+PrintGCDetails,执行结果如下:
[GC [PSYoungGen: 1019K->568K(28672K)] 1019K->568K(92672K), 0.0529244 secs] [Times: user=0.00 sys=0.00, real=0.06 secs]
{博主自定义注解:[GC [新生代: MinorGC前新生代内存使用->MinorGC后新生代内存使用(新生代总的内存大小)] MinorGC前JVM堆内存使用的大小->MinorGC后JVM堆内存使用的大小(堆的可用内存大小), MinorGC总耗时] [Times: 用户耗时=0.00 系统耗时=0.00, 实际耗时=0.06 secs] }
[Full GC [PSYoungGen: 568K->0K(28672K)] [ParOldGen: 0K->478K(64000K)] 568K->478K(92672K) [PSPermGen: 2484K->2483K(21504K)], 0.0178331 secs] [Times: user=0.01 sys=0.00, real=0.02 secs]
{博主自定义注解:[Full GC [PSYoungGen: 568K->0K(28672K)] [老年代: FullGC前老年代内存使用->FullGC后老年代内存使用(老年代总的内存大小)] FullGC前JVM堆内存使用的大小->FullGC后JVM堆内存使用的大小(堆的可用内存大小) [永久代: 2484K->2483K(21504K)], 0.0178331 secs] [Times: user=0.01 sys=0.00, real=0.02 secs]}
[GC [PSYoungGen: 501K->64K(28672K)] 980K->542K(92672K), 0.0005080 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[Full GC [PSYoungGen: 64K->0K(28672K)] [ParOldGen: 478K->479K(64000K)] 542K->479K(92672K) [PSPermGen: 2483K->2483K(21504K)], 0.0133836 secs] [Times: user=0.05 sys=0.00, real=0.01 secs]
Heap
PSYoungGen total 28672K, used 1505K [0x00000000e0a00000, 0x00000000e2980000, 0x0000000100000000)
eden space 25088K, 6% used [0x00000000e0a00000,0x00000000e0b78690,0x00000000e2280000)
from space 3584K, 0% used [0x00000000e2600000,0x00000000e2600000,0x00000000e2980000)
to space 3584K, 0% used [0x00000000e2280000,0x00000000e2280000,0x00000000e2600000)
ParOldGen total 64000K, used 479K [0x00000000a1e00000, 0x00000000a5c80000, 0x00000000e0a00000)
object space 64000K, 0% used [0x00000000a1e00000,0x00000000a1e77d18,0x00000000a5c80000)
PSPermGen total 21504K, used 2492K [0x000000009cc00000, 0x000000009e100000, 0x00000000a1e00000)
object space 21504K, 11% used [0x000000009cc00000,0x000000009ce6f2d0,0x000000009e100000)
注:你可以用JConsole或者Runtime.getRuntime().maxMemory(),Runtime.getRuntime().totalMemory(), Runtime.getRuntime().freeMemory()来查看Java中堆内存的大小。
再看一个例子:
package jvm;
public class PrintGCDetails2
{
/**
* -Xms60m -Xmx60m -Xmn20m -XX:NewRatio=2 ( 若 Xms = Xmx, 并且设定了 Xmn,
* 那么该项配置就不需要配置了 ) -XX:SurvivorRatio=8 -XX:PermSize=30m -XX:MaxPermSize=30m
* -XX:+PrintGCDetails
*/
public static void main(String[] args)
{
new PrintGCDetails2().doTest();
}
public void doTest()
{
Integer M = new Integer(1024 * 1024 * 1); // 单位, 兆(M)
byte[] bytes = new byte[1 * M]; // 申请 1M 大小的内存空间
bytes = null; // 断开引用链
System.gc(); // 通知 GC 收集垃圾
System.out.println();
bytes = new byte[1 * M]; // 重新申请 1M 大小的内存空间
bytes = new byte[1 * M]; // 再次申请 1M 大小的内存空间
System.gc();
System.out.println();
}
}
运行结果:
[GC [PSYoungGen: 2007K->568K(18432K)] 2007K->568K(59392K), 0.0059377 secs] [Times: user=0.02 sys=0.00, real=0.01 secs]
[Full GC [PSYoungGen: 568K->0K(18432K)] [ParOldGen: 0K->479K(40960K)] 568K->479K(59392K) [PSPermGen: 2484K->2483K(30720K)], 0.0223249 secs] [Times: user=0.01 sys=0.00, real=0.02 secs]
[GC [PSYoungGen: 3031K->1056K(18432K)] 3510K->1535K(59392K), 0.0140169 secs] [Times: user=0.05 sys=0.00, real=0.01 secs]
[Full GC [PSYoungGen: 1056K->0K(18432K)] [ParOldGen: 479K->1503K(40960K)] 1535K->1503K(59392K) [PSPermGen: 2486K->2486K(30720K)], 0.0119497 secs] [Times: user=0.02 sys=0.00, real=0.01 secs]
Heap
PSYoungGen total 18432K, used 163K [0x00000000fec00000, 0x0000000100000000, 0x0000000100000000)
eden space 16384K, 1% used [0x00000000fec00000,0x00000000fec28ff0,0x00000000ffc00000)
from space 2048K, 0% used [0x00000000ffe00000,0x00000000ffe00000,0x0000000100000000)
to space 2048K, 0% used [0x00000000ffc00000,0x00000000ffc00000,0x00000000ffe00000)
ParOldGen total 40960K, used 1503K [0x00000000fc400000, 0x00000000fec00000, 0x00000000fec00000)
object space 40960K, 3% used [0x00000000fc400000,0x00000000fc577e10,0x00000000fec00000)
PSPermGen total 30720K, used 2493K [0x00000000fa600000, 0x00000000fc400000, 0x00000000fc400000)
object space 30720K, 8% used [0x00000000fa600000,0x00000000fa86f4f0,0x00000000fc400000)
从打印结果可以看出,堆中新生代的内存空间为 18432K ( 约 18M ),eden 的内存空间为 16384K ( 约 16M),from / to survivor 的内存空间为 2048K ( 约 2M)。
这里所配置的 Xmn 为 20M,也就是指定了新生代的内存空间为 20M,可是从打印的堆信息来看,新生代怎么就只有 18M 呢? 另外的 2M 哪里去了?
别急,是这样的。新生代 = eden + from + to = 16 + 2 + 2 = 20M,可见新生代的内存空间确实是按 Xmn 参数分配得到的。
而且这里指定了 SurvivorRatio = 8,因此,eden = 8/10 的新生代空间 = 8/10 * 20 = 16M。from = to = 1/10 的新生代空间 = 1/10 * 20 = 2M。
堆信息中新生代的 total 18432K 是这样来的: eden + 1 个 survivor = 16384K + 2048K = 18432K,即约为 18M。
因为 jvm 每次只是用新生代中的 eden 和 一个 survivor,因此新生代实际的可用内存空间大小为所指定的 90%。
因此可以知道,这里新生代的内存空间指的是新生代可用的总的内存空间,而不是指整个新生代的空间大小。
另外,可以看出老年代的内存空间为 40960K ( 约 40M ),堆大小 = 新生代 + 老年代。因此在这里,老年代 = 堆大小 – 新生代 = 60 – 20 = 40M。
最后,这里还指定了 PermSize = 30m,PermGen 即永久代 ( 方法区 ),它还有一个名字,叫非堆,主要用来存储由 jvm 加载的类文件信息、常量、静态变量等。
附:JVM常用参数
-XX:+<option> 启用选项
-XX:-<option>不启用选项
-XX:<option>=<number>
-XX:<option>=<string>
堆设置
-Xms :初始堆大小
-Xmx :最大堆大小
-Xmn:新生代大小。通常为 Xmx 的 1/3 或 1/4。新生代 = Eden + 2 个 Survivor 空间。实际可用空间为 = Eden + 1 个 Survivor,即 90%
-XX:NewSize=n :设置年轻代大小
-XX:NewRatio=n: 设置年轻代和年老代的比值。如:为3,表示年轻代与年老代比值为1:3,年轻代占整个年轻代年老代和的1/4
-XX:SurvivorRatio=n :年轻代中Eden区与两个Survivor区的比值。注意Survivor区有两个。如:3,表示Eden:Survivor=3:2,一个Survivor区占整个年轻代的1/5
-XX:PermSize=n 永久代(方法区)的初始大小
-XX:MaxPermSize=n :设置永久代大小
-Xss 设定栈容量;对于HotSpot来说,虽然-Xoss参数(设置本地方法栈大小)存在,但实际上是无效的,因为在HotSpot中并不区分虚拟机和本地方法栈。
-XX:PretenureSizeThreshold (该设置只对Serial和ParNew收集器生效) 可以设置进入老生代的大小限制
-XX:MaxTenuringThreshold=1(默认15)垃圾最大年龄 如果设置为0的话,则年轻代对象不经过Survivor区,直接进入年老代. 对于年老代比较多的应用,可以提高效率.如果将此值设置为一个较大值,则年轻代对象会在Survivor区进行多次复制,这样可以增加对象再年轻代的存活 时间,增加在年轻代即被回收的概率
该参数只有在串行GC时才有效.
收集器设置
-XX:+UseSerialGC :设置串行收集器
-XX:+UseParallelGC :设置并行收集器
-XX:+UseParallelOldGC :设置并行年老代收集器
-XX:+UseConcMarkSweepGC :设置并发收集器
垃圾回收统计信息
-XX:+PrintHeapAtGC GC的heap详情
-XX:+PrintGCDetails GC详情
-XX:+PrintGCTimeStamps 打印GC时间信息
-XX:+PrintTenuringDistribution 打印年龄信息等
-XX:+HandlePromotionFailure 老年代分配担保(true or false)
-Xloggc:gc.log 指定日志的位置
并行收集器设置
-XX:ParallelGCThreads=n :设置并行收集器收集时使用的CPU数。并行收集线程数。
-XX:MaxGCPauseMillis=n :设置并行收集最大暂停时间
-XX:GCTimeRatio=n :设置垃圾回收时间占程序运行时间的百分比。公式为1/(1+n)
并发收集器设置
-XX:+CMSIncrementalMode :设置为增量模式。适用于单CPU情况。
-XX:ParallelGCThreads=n :设置并发收集器年轻代收集方式为并行收集时,使用的CPU数。并行收集线程数。
其他
-XX:PermSize=10M和-XX:MaxPermSize=10M限制方法区大小。
-XX:MaxDirectMemorySize=10M指定DirectMemory(直接内存)容量,如果不指定,则默认与JAVA堆最大值(-Xmx指定)一样。
-XX:+HeapDumpOnOutOfMemoryError 可以让虚拟机在出现内存溢出异常时Dump出当前的内存堆转储快照(.hprof文件)以便时候进行分析(比如Eclipse Memory Analysis)。
参考资料:
1. 《java 虚拟机–新生代与老年代GC》
2. 《Java 堆内存》
3. 《深入理解Java虚拟机》周志明著











